


数据分析应用场景整理
(1)某银行业务数据分析和挖掘
预测客户办理业务的可能性;
检验促销活动的有效性。
内容概要
●首先,对某银行某次营销活动受众客户的特征进行了描述性统计,考察了营销活动的总体效果;同时还进行了特征间的相关性分析,筛掉了与响应行为之间没有显著相关性的特征;
●其次,分别考察了存款和个贷客户在年龄、年收入等6个特征上的分布情况,分析了存款和个贷客户的自然属性和消费行为特征,并据此构建了存款客户画像和个贷客户画像;
●然后,运用Apriori关联规则算法分析了各类业务之间的关联,并重点总结出了存款客户中潜在个贷客户的特征;
●接着,根据以上分析结果尝试为该银行扩大各类业务客户基数,提高获客能力提出建议;
●最后,根据分析出的个贷客户画像对客户是否办理个贷业务进行建模,得出最优分类器;当有新的客户数据时便可以使用该模型对客户办理个贷业务的可能性进行预测。
关键词
●python
●客户画像
●二分类
●关联分析
内容大纲
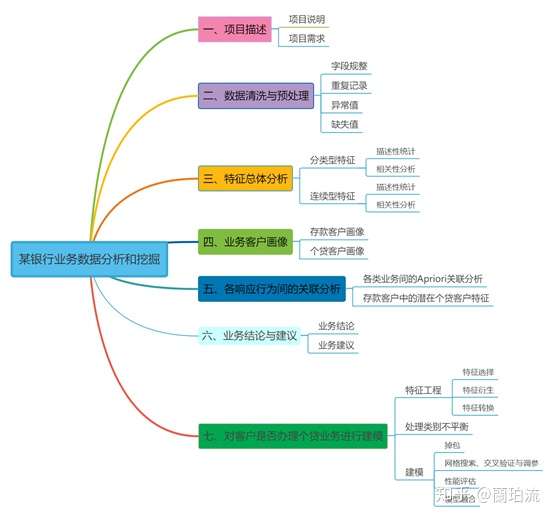
一、项目描述
1、项目说明
(1)数据来源:本项目所用数据来源于kaggle平台,该数据集展示了某银行某年一次贷款营销活动的5,000条客户信息记录。
(2)使用工具:本项目的分析和可视化都是使用python完成的,但相关性分析用到了SPSS。
(3)数据描述:数据字典如下表所示:
表1 数据字典

2、业务需求
2.1业务背景
某银行是一家客户群不断增长的银行,但其贷款业务的客户基数较小,因此该行希望能够将存款用户转化为贷款用户,扩大贷款业务量,从而赚取更多的存贷利差。为此,该行零售信贷部于2016年针对部分客户开展了一次推广个人贷款业务的营销活动,并希望通过数据分析识别出办理个贷业务的潜在客户。
2.2提出问题
(1)该次营销活动的受众客户中有多少办理了该行的有关业务,各类业务的获客情况如何。
(2)办理了存款和个贷业务的客户分别具备什么样的共性特征。
(3)存款客户到个贷客户的转化率有多少,具备怎样特征的存款客户能够有效转化成个贷客户。
(4)根据个贷客户画像对客户是否办理个贷业务进行建模。
二、数据清洗与预处理
导入库并预览数据
import numpy as np,pandas as pd,matplotlib.pyplot as plt,seaborn as sns
url='C:/Users/lelelan/Desktop/Exercises and Projects/dataset/credit/Bank_Personal_Loan_Modelling.xlsx'
df=pd.read_excel(url,sheet_name='Data')
df.head(5)
查看字段名的规范性
df.columns
修改字段名为中文名
df.columns=['ID','年龄','工作经验','年收入','邮编','家庭规模','月均信用卡消费额','文化程度',
'押品价值','个贷客户','证券客户','存款客户','网上银行','信用卡客户']去掉金额字段的单位符号
for x in ['年收入','月均信用卡消费额','押品价值']:df[x]=df[x].str[:-2] 查看各字段类型
df.dtypes
修正ID、年收入、月均信用卡消费额和押品价值四个字段的类型
df['ID']=df.ID.astype('object')
for x in ['年收入','押品价值']:df[x]=df[x].astype('int64')
df.月均信用卡消费额=round(df.月均信用卡消费额.astype('float64'),2)删除邮编字段
df.drop('邮编',axis=1,inplace=True)删除重复记录
df.drop_duplicates(inplace=True)
df[df.duplicated()].ID.count()
对数值型字段进行描述性统计,并查看异常值
df.describe().T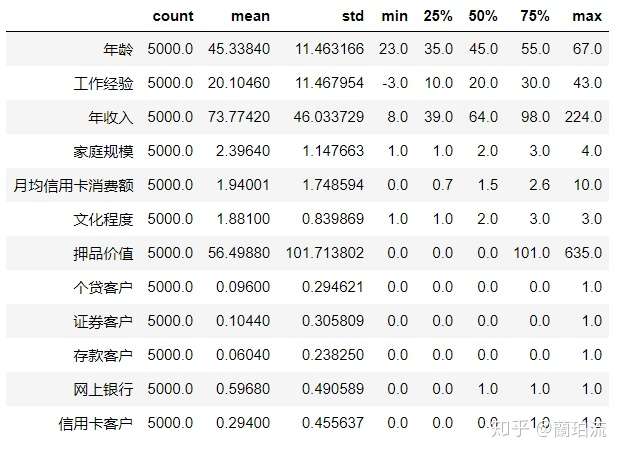
分析:
(1)连续型特征:年龄和工作经验的均值与中位数比较相近,说明二者分布比较均匀,但它们的标准差不低,说明年龄和工作经验的分布比较广;年收入、月均信用卡消费额和押品价值的均值都比中位数高,说明它们都呈右偏分布,存在极大值;其中年收入和押品价值的标准差非常大,右偏程度很高;尤其是押品价值的中位数为0,可见50%以上的客户没有住房抵押。
(2)类别型特征:从5个二分类字段的均值可以得出,办理了信用卡业务的客户数占抽样所得客户总数的比例约为29.40%;办理了证券业务的客户占比约为10.44%;办理了个贷业务的客户占比约为9.60%;办理了存款业务的客户占比约为6.04%;使用网上银行的客户占比约为59.68%。
先将工作经验字段为负数的记录另存并删除,便于接下来的描述性统计分析
df2=df.loc[df.工作经验<0]
df.drop(df2.index,inplace=True)
df.loc[df.工作经验<0,'ID'].count()
查看各字段的缺失值数量
df.isnull().sum()
可见不存在缺失值
三、特征总体分析
1、分类型特征
1.1描述性统计:频数和比例
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rc('font',size=13)
width=0.4
fig,axes=plt.subplots(2,4,sharey=True,figsize=(15,10))
def pltbar(m,n,index,unit):
data=df.groupby(index).ID.count()
ratiodata=data/df.ID.count()
x=np.arange(len(data))
axes[m,n].set_xticks(x)
axes[m,n].set_ylabel('人数')
axes[m,n].bar(x-width/2,data,width=width)
for a,b in zip(x-width/2-0.08,data):
axes[m,n].text(a,b,b,ha='center',va='bottom',color='k')
axes[m,n].set_xticklabels(data.index)
axes[m,n].set_xlabel(index+unit)
axes2=axes[m,n].twinx()
axes2.bar(x+width/2,ratiodata,width=width,label='比例',color='#f97306')
for a,b in zip(x+width/2,ratiodata):
axes2.text(a,b,'%.2f%%'%(b*100),ha='center',va='bottom',color='k')
axes2.legend(loc='best')
plt.subplots_adjust(wspace=0.3)
pltbar(0,0,'家庭规模','(人)')
pltbar(0,1,'文化程度','')
pltbar(0,2,'个贷客户','')
pltbar(0,3,'证券客户','')
pltbar(1,0,'存款客户','')
pltbar(1,1,'网上银行','')
pltbar(1,2,'信用卡客户','')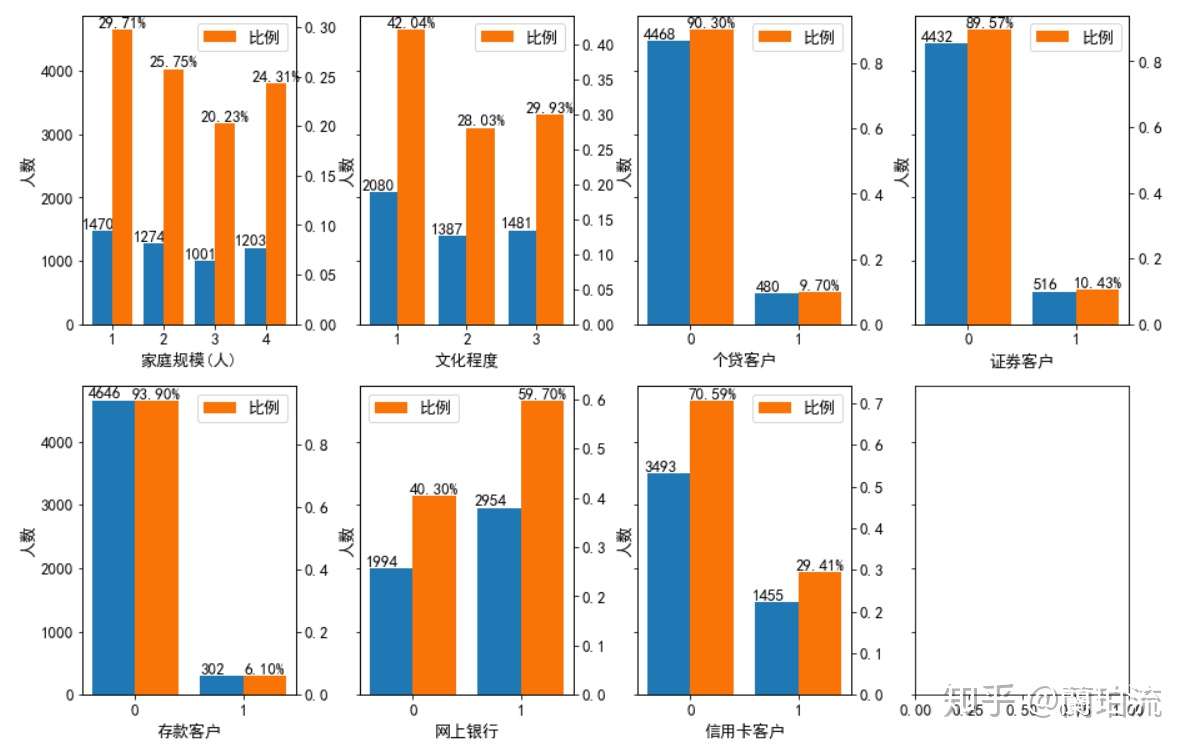
分析:
(1)家庭规模方面:家庭规模为1人,即单身的客户最多;客户次多的家庭规模从高到低依次是2人、4人和3人;但这4种家庭规模的客户数量彼此差异不大,占客户总数的比例都在20%到30%之间,分布较为均匀。
(2)文化程度方面:本科学历以下的客户最多,但文化程度在本科毕业及以上的客户数合计占比超过了一半,可见该行客户以受过大学本科教育的客户为主。
(3)响应行为方面:未办理个贷、证券、存款和信用卡业务的客户要远多于办理了相应业务的客户,可见该次营销活动的受众中只有很少一部分办理过该行的有关业务。
1.2相关性分析
(1)通过SPSS借助皮尔逊卡方独立性检验对各分类型字段之间的相关性进行分析,得到检验结果的显著性水平如下表
表2 分类型特征的皮尔逊卡方独立性检验
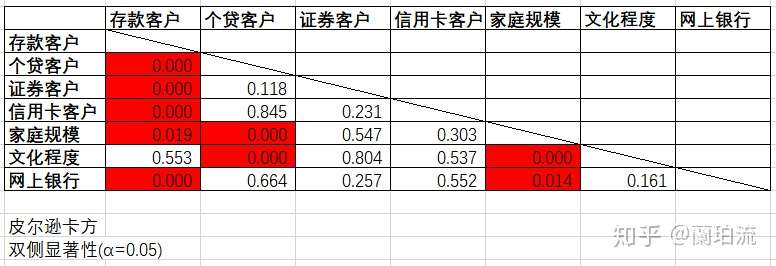
(2)通过卡方独立性检验可以得出,文化程度与是否为存款客户之间没有显著相关性;是否为证券客户、是否为信用卡客户、是否使用网上银行与是否为个贷客户之间没有显著相关性,是否为证券客户与是否为信用卡客户、家庭规模、文化程度和是否使用网上银行间没有显著相关性;是否为信用卡客户与家庭规模、文化程度、网上银行之间没有显著相关性。
(3)基于卡方独立性检验的结果,在分析客户画像时将不考虑与响应行为之间没有显著相关性的特征,即在分析存款客户画像时,将不考虑“文化程度”特征;在分析个贷客户画像时,将不考虑“证券客户”、“信用卡客户”和“网上银行”这三个特征。
2、连续型特征:数值分布与相关性分析
2.1矩阵散点图
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rc('font',size=13)
sns.pairplot(df.loc[:,['年龄','工作经验','年收入','月均信用卡消费额','押品价值']],diag_kind='kde',aspect=1.8)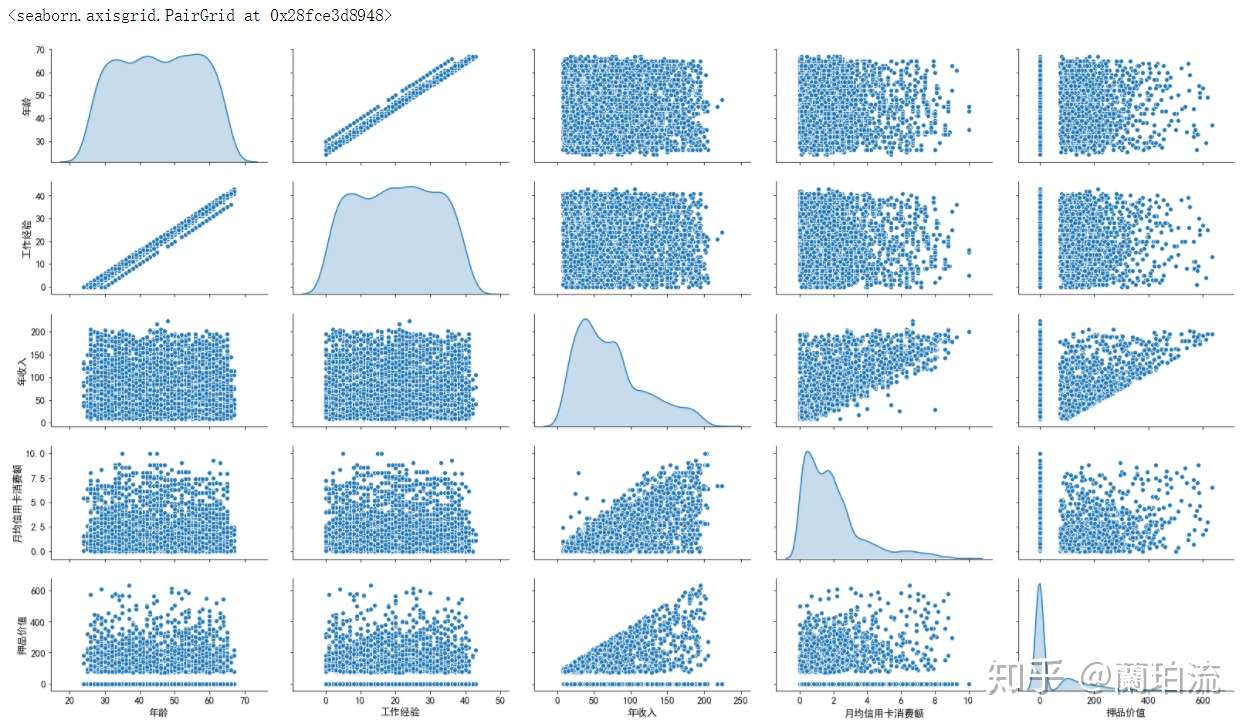
2.2皮尔逊相关系数矩阵
通过SPSS借助因子分析得到各连续型特征之间的皮尔逊相关系数,如下表所示
表3 连续型特征的皮尔逊相关系数矩阵
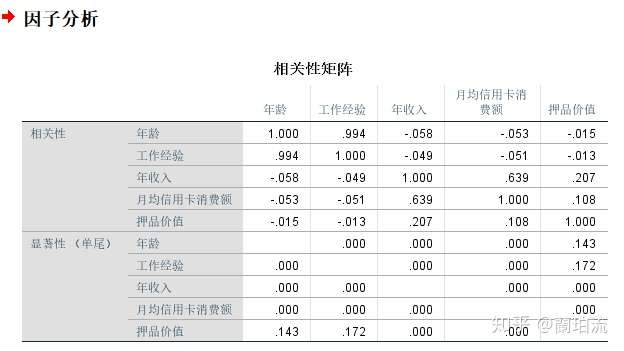
分析:
(1)数值分布分析:该行客户总体上年龄集中在30岁到60岁之间,但36和46岁的客户要比相邻年龄的客户少一些;工龄集中在7到34年;年收入集中在4万到7.5万美元间;月均信用卡消费额集中在0.5到2千美元间;押品价值集中在0值上,说明绝大部分客户没有住房抵押,但押品价值的核密度在10万美元处有一个极值,说明有住房抵押的客户大部分押品价值都在10万美元左右。
(2)相关性分析:由相关性矩阵和散点图可以看出,年龄与年收入(r=-0.058,p=0.000<0.05)以及月均信用卡消费额(r=-0.053,p=0.000<0.05)之间的相关性较弱;工作经验与年龄具有高度的正相关性(r=0.994,p=0.000<0.05),而与年收入(r=-0.049,p=0.000<0.05)和月均信用卡消费额。(r=-0.051,p=0.000<0.05)之间的相关性较弱;年收入越高,月均信用卡消费额(r=0.639,p=0.000<0.05)和押品价值(r=0.207,p=0.000<0.05)的上限越高。
四、存贷款业务客户画像
1、存款客户画像
1.1存款和非存款客户在年龄、年收入、月均信用卡消费额和押品价值上的分布差异
def multi_kde(data,pointsnum,unit):
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rc('font',size=13)
i=data.shape[1]
a=data.columns.values[0]
fig,axes=plt.subplots(1,i-1,figsize=(20,5))
for j,k in zip(np.arange(1,i),np.arange(i-1)):
b=data[data[a]==0]
c=data[data[a]==1]
d=data.iloc[:,j]
e=np.array(unit)
plt.xticks(np.arange(d.min(),d.max(),int((d.max()-d.min())/pointsnum)))
axes[k].set_xlabel(data.columns.values[j]+e[k])
b.iloc[:,j].plot.kde(ax=axes[k])
c.iloc[:,j].plot.kde(ax=axes[k])
axes[k].legend(labels=['非'+a,a],loc='best',fontsize=10)
plt.subplots_adjust(wspace=0.3)
multi_kde(df.loc[:,['存款客户','年龄','年收入','月均信用卡消费额','押品价值']],5,['','(k$)','(k$)','(k$)'])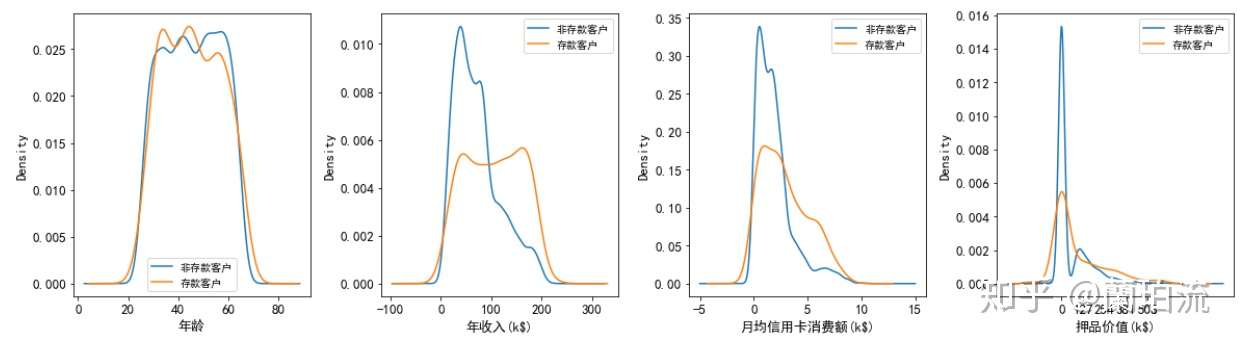
补充:对押品价值进行分箱分析
def cutbar(data1,data2,num,xlabel,ylabel,data1label,data2label):
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rc('font',size=13)
fig,axes=plt.subplots(1,1,sharey=True,figsize=(10,6))
axes.set_xlabel('押品价值区间')
axes.set_ylabel('人数')
width=0.4
x=np.arange(num)
axes.set_xticks(x)
axes.bar(x-width/2,data1,width=width,label=data1label)
axes.bar(x+width/2,data2,width=width,label=data2label)
axes.legend(loc='best')
axes.set_xticklabels(data1.index.values,rotation=30)
for a,b in zip(x-width/2,data1):
axes.text(a,b,b,ha='center',va='bottom',color='k')
for a,b in zip(x+width/2,data2):
axes.text(a,b,b,ha='center',va='bottom',color='k')
a=sorted(list(set(np.concatenate([np.linspace(0,60,6),np.linspace(60,df.押品价值.max(),6)],axis=0))))
df['押品价值分箱']=pd.cut(df.押品价值,a,right=False,precision=0)
bardata_cdmor=df[df.存款客户==1].groupby('押品价值分箱').ID.count()
bardata_notcdmor=df[df.存款客户==0].groupby('押品价值分箱').ID.count()
cutbar(bardata_notcdmor,bardata_cdmor,10,'押品价值区间','人数','非存款客户','存款客户')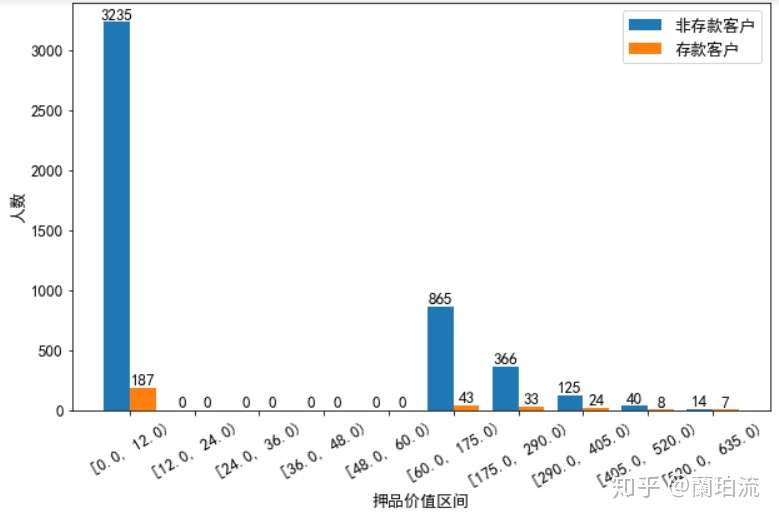
分析:
(1)在年龄的分布上:存款客户的年龄集中在33到55岁之间,这其中年龄在33岁到45岁之间的客户要多于其他年龄段的客户,可见存款客户以青中年为主。
(2)在年收入的分布上:非存款客户的年收入呈右偏分布,但整体集中在4万美元左右,说明非存款客户以中低收入为主;而存款客户的年收入分布相对广泛且均匀,集中在4万到16万美元之间。
(3)在月均信用卡消费额的分布上:存款和非存款客户的月均信用卡消费额都集中在1千美元左右,可见两类客户信用卡消费水平整体都不高;但存款客户的月均信用卡消费额呈右偏分布,存在高消费水平的客户。
(4)在押品价值的分布上:存款和非存款客户的押品价值都集中在0值附近,进一步对押品价值分箱处理后发现,存款和非存款客户中绝大多数都没有住房抵押(押品价值为0),而有住房抵押的存款客户其押品价值在6万到17.5万美元间的最多,有住房抵押的非存款客户其押品价值在10万美元左右的最多(其核密度曲线在10万美元处有一极值),同时随着押品价值的升高存款和非存款客户的数量都越来越少。
1.2存款和非存款客户在家庭规模上的分布差异
piedata_cd=df.groupby('存款客户').ID.count()
df['家庭规模(人)']=df.家庭规模.apply(lambda x:'%d人'%(x))
piedata_cdfam=df.groupby(['存款客户','家庭规模(人)']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
def sunfig(data_level1,data_level2,bbox_to_anchor_left,pctdistance1,pctdistance2,labeldistance):
plt.rcParams['font.sans-serif'] =['SimHei']
plt.figure(figsize=(6,6))
cmap=plt.get_cmap("tab20c")
points=np.arange(len(data_level2.index.levels[0]))*4
inner_colors=cmap(points)
outer_colors=cmap(points.repeat([len(data_level2[0]),len(data_level2[1])]))
wedges,texts,autotexts=plt.pie(data_level1.values,radius=1,autopct='%1.2f%%',pctdistance=pctdistance1,
textprops={'fontsize':15},colors=inner_colors,wedgeprops=dict(width=1,edgecolor='k'))
plt.legend(wedges,title="是否为%s"%(data_level2.index.get_level_values(0).name),labels=data_level1.index.get_level_values(0),fontsize=12,
bbox_to_anchor=(bbox_to_anchor_left,0,0.7,1))
plt.pie(data_level2.values,radius=1+0.7,autopct='%1.2f%%',labels=data_level2.index.get_level_values(1),
pctdistance=pctdistance2,labeldistance=labeldistance,
textprops={'fontsize':13},colors=outer_colors,wedgeprops=dict(width=0.7,edgecolor='k'))
plt.axis('equal')
sunfig(piedata_cd,piedata_cdfam,0.45,0.5,0.8,1.05)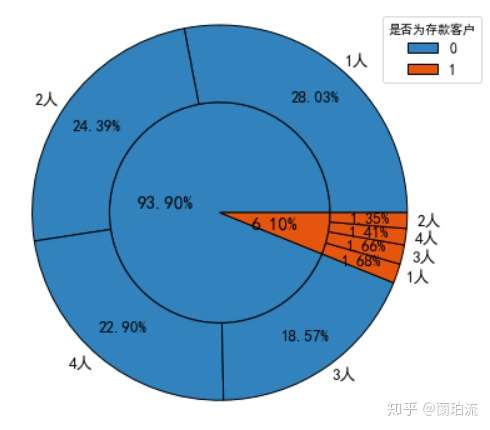
分析:家庭规模为1人,即处于单身或离异状态的客户在存款和非存款客户中的占比都是最大的;但在存款客户中家庭规模为3人和4人,即已婚且有子女的客户占比要高于家庭规模为2人即已婚但未育的客户。
2、个贷客户画像
2.1个贷和非个贷客户在年龄、年收入、月均信用卡消费额和押品价值上的分布差异
multi_kde(df.loc[:,['个贷客户','年龄','年收入','月均信用卡消费额','押品价值']],5,['','(k$)','(k$)','(k$)'])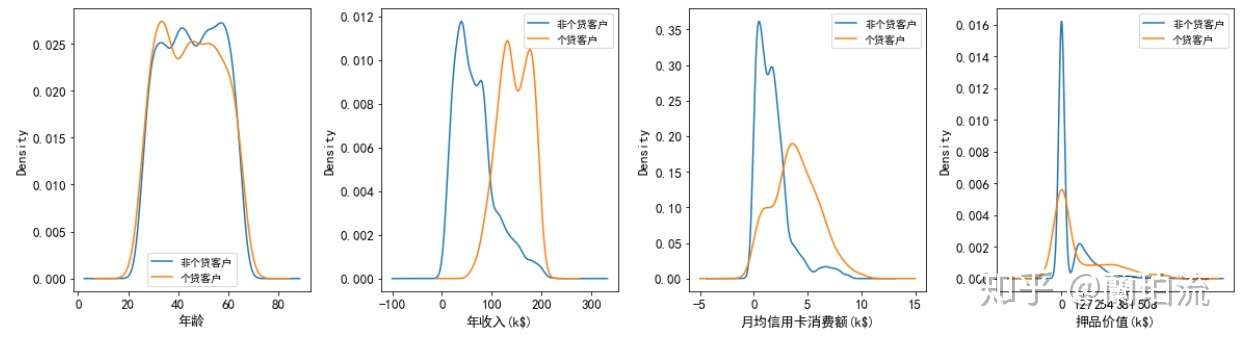
补充:对押品价值进行分箱分析
df['押品价值分箱']=pd.cut(df.押品价值,a,right=False,precision=0)
bardata_loamor=df[df.个贷客户==1].groupby('押品价值分箱').ID.count()
bardata_notloamor=df[df.个贷客户==0].groupby('押品价值分箱').ID.count()
cutbar(bardata_notloamor,bardata_loamor,10,'押品价值区间','人数','非个贷客户','个贷客户')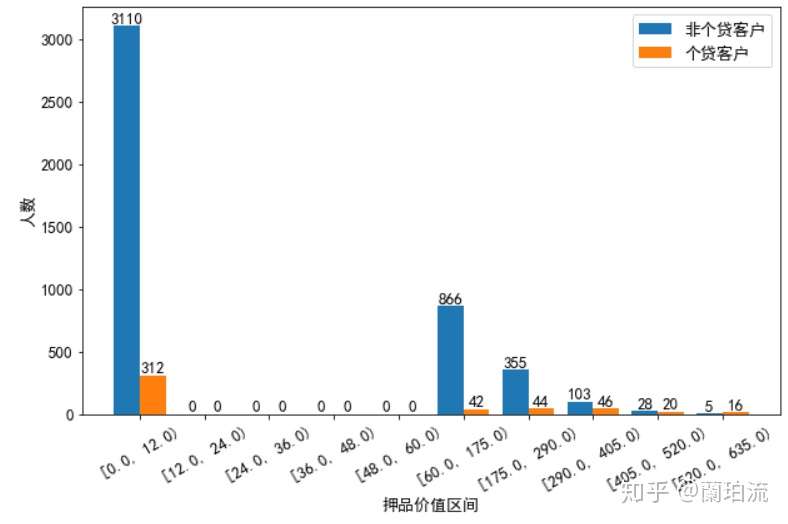
分析:
(1)在年龄的分布上:个贷客户的年龄主要集中在32岁到50岁之间,这其中32到38岁的客户要多于其他年龄段的客户,同时40岁左右的客户要比相邻年龄的客户少。
(2)在年收入的分布上:非个贷客户年收入呈右偏分布,但集中在4万到8万美元左右,以中低收入为主;而个贷客户的年收入分布相对均匀,集中在13万美元到17.5万美元间,以中高收入为主;同时在9.8万美元右侧,个贷客户的核密度曲线呈急剧上升,而非个贷客户的核密度曲线在急剧下降,可见年收入9.8万美元是个分界点,年收入高于该水平的客户更有可能办理个贷业务。
(3)在月均信用卡消费额的分布上:非个贷客户的月均信用卡消费额呈右偏分布,但集中在0.5到1.7千美元之间,消费水平整体偏低;而个贷客户的月均信用卡消费额分布相对均匀,并集中在3.5千美元左右,以中高消费水平为主。同时在2.8千美元右侧,个贷客户的核密度曲线呈急剧上升并很快达到峰值,而非个贷客户的核密度曲线呈急剧下降,可见2.8千美元是一个分界点,月均信用卡消费额高于该水平的客户更有可能办理个贷业务。
(4)在押品价值的分布上:个贷和非个贷客户的押品价值都集中在0值附近,进一步对押品价值分箱处理后发现,个贷和非个贷客户中绝大多数都没有住房抵押(押品价值为0),且个贷客户中有住房抵押的其押品价值在29万到40.5万美元间的最多,并且当押品价值在6万到40.5万美元之间时,随着押品价值的升高个贷客户的数量在增多,而非个贷客户的数量在减少。
2.2个贷和非个贷客户在信用卡还款压力上的分布差异
计算年信用卡消费额占年均收入的比重可以得出客户对信用卡的使用程度,也能反映客户信用卡的还款压力
df['信用卡-收入比']=round(df.月均信用卡消费额*12/df.年收入,3)
plt.rcParams['font.sans-serif'] =['SimHei']
plt.figure(figsize=(8,6))
plt.xlabel('信用卡-收入比')
plt.xticks(np.arange(df['信用卡-收入比'].min(),df['信用卡-收入比'].max(),
round((df['信用卡-收入比'].max()-df['信用卡-收入比'].min())/10,1)))
df.loc[df.个贷客户==0,'信用卡-收入比'].plot.kde(label='非个贷客户')
df.loc[df.个贷客户==1,'信用卡-收入比'].plot.kde(label='个贷客户')
plt.legend(loc='upper right',fontsize=10)
plt.ylabel('核密度')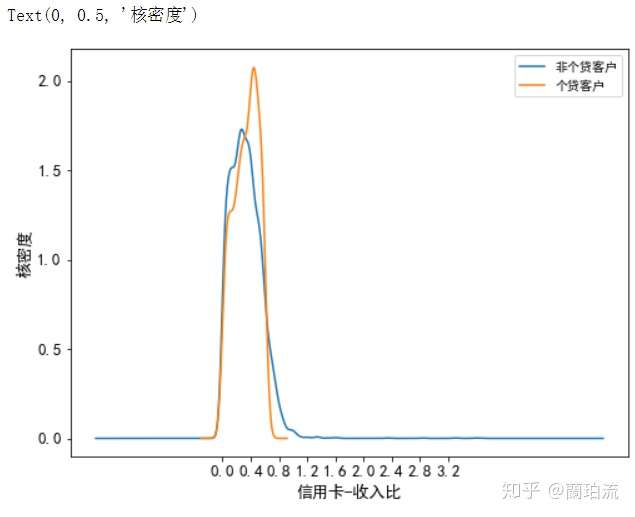
分析:非个贷客户的信用卡消费额占其收入的比重集中在20%左右,而个贷客户的信用卡消费额占其收入的比重集中在40%左右;同时,在20%到40%这一区间内,非个贷客户的核密度曲线急剧下降,而个贷客户的核密度曲线急剧上升并达到峰值,可见信用卡-收入比在30%到40%之间的客户办理个贷业务的倾向最强。但当信用卡消费额占收入的比重超过65%以后,个贷客户数量的下降幅度要大于非个贷客户,可见虽然大部分非个贷客户对信用卡的使用较为保守,但也存在小部分不理性使用信用卡的客户。
2.3个贷和非个贷客户在家庭规模上的分布差异
piedata_loa=df.groupby('个贷客户').ID.count()
piedata_loafa=df.groupby(['个贷客户','家庭规模(人)']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
sunfig(piedata_loa,piedata_loafa,0.5,0.5,0.8,1.05)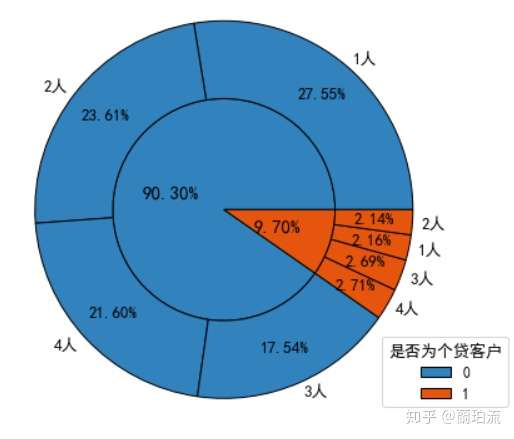
分析:非个贷客户以独身或已婚未育为主,而个贷客户则以已婚有子女为主。
2.4个贷和非个贷客户在文化程度上的分布差异
def wenhua(x):
if x==1:
return '本科以下'
elif x==2:
return '本科毕业'
else:
return '更高'
df['文化程度2']=df.文化程度.apply(lambda x:wenhua(x))
piedata_loaedu=df.groupby(['个贷客户','文化程度2']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
sunfig(piedata_loa,piedata_loaedu,0.47,0.5,0.8,1.05)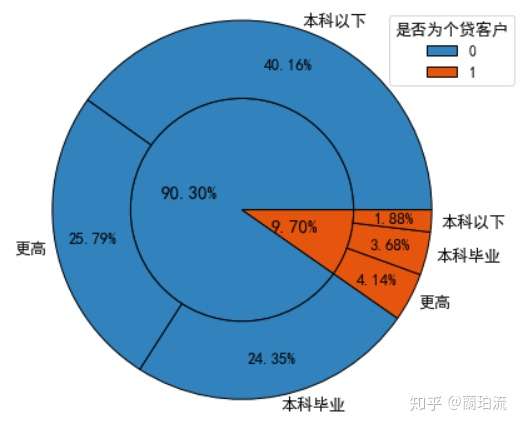
分析:文化程度在本科以下的客户在非个贷客户中的占比最高,达到了44.31%(40.06%/90.04%),而在个贷客户中的占比最低,仅为19.37%(1.86%/9.60%),个贷客户中本科毕业及以上学历的客户合计约占其80.63%((3.64%+4.10%)/9.60%),可见受过大学本科教育的客户办理个贷业务的意识更强。
五、各响应行为间的关联分析
1、各类业务间的Apriori关联分析
#导入Apriori关联规则算法包
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules(1)设定最小支持度为0.04,挖掘频繁项集
frequent_itemsets=apriori(df.iloc[:,-5:],min_support=0.04,use_colnames=True).sort_values('support',ascending=False)
frequent_itemsets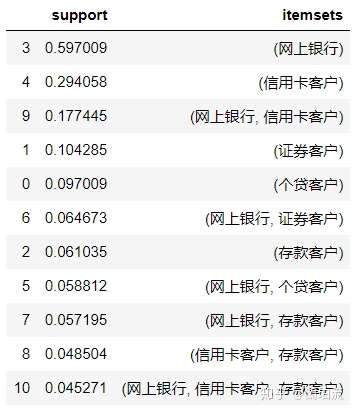
分析:通过上表可知,该行同时办理信用卡和网上银行业务的客户占比约为17.74%;同时办理证券和网上银行业务的客户占比约为6.47%;同时办理个贷和网上银行业务的客户占比约为5.88%;同时办理存款和网上银行业务的客户占比约为5.72%;同时办理存款和信用卡业务的客户占比约为4.85%;同时办理存款、信用卡和网上银行业务的客户占比约为4.53%。
(2)设定最小置信度为0.7,挖掘强关联规则
rules=association_rules(frequent_itemsets,metric='confidence',min_threshold=0.7).sort_values('confidence',ascending=False)
rules
分析:
1)通过上表可知,客户如果办理了存款业务,那么就有93.71%的概率会开通网上银行,有79.47%的概率会办理信用卡业务,有74.17%的概率会同时办理信用卡和网上银行业务;客户如果同时办理了存款和信用卡业务,那么就有93.33%的概率会开通网上银行;客户如果同时办理了存款和网上银行业务,那么就有79.15%的概率会办理信用卡业务。
2)通过以上分析可以看出,绝大部分存款客户都会同时办理信用卡或网上银行业务,可见存款业务对这两个业务具有很好的衍生作用,但并未看到存款业务对个贷业务的衍生作用,可见该行并没有把存款客户有效地转化为个贷客户。
(3)查看存款客户中个贷客户的比例
df['是否个贷']=df.个贷客户.apply(lambda x:'个贷客户' if x==1 else '非个贷客户')
piedata_cdloa=df.groupby(['存款客户','是否个贷']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
sunfig(piedata_cd,piedata_cdloa,0.46,0.5,0.8,1.05)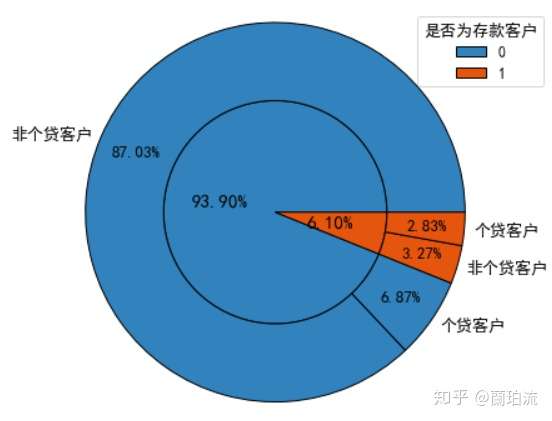
分析:存款客户中办理了个贷业务的客户占比,即该次营销活动的转化率为46.39%(2.83%/6.10%),可见超过一半的存款客户并没有办理个贷业务,因而需要挖掘存款客户中潜在个贷客户的特征,针对这部分客户进行个贷业务的精准营销,以提高存款到个贷客户的转化率。
2、存款客户中的潜在个贷客户特征
(1)既存款又个贷的客户与存款但非个贷客户在年龄、年收入、信用卡消费水平以及押品价值方面的差异
data_cd=df[df.存款客户==1]
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rc('font',size=13)
sns.pairplot(data_cd.loc[:,['个贷客户','年龄','年收入','月均信用卡消费额','信用卡-收入比','押品价值']],
vars=['年龄','年收入','月均信用卡消费额','信用卡-收入比','押品价值'],hue='个贷客户',diag_kind='kde',aspect=1.8)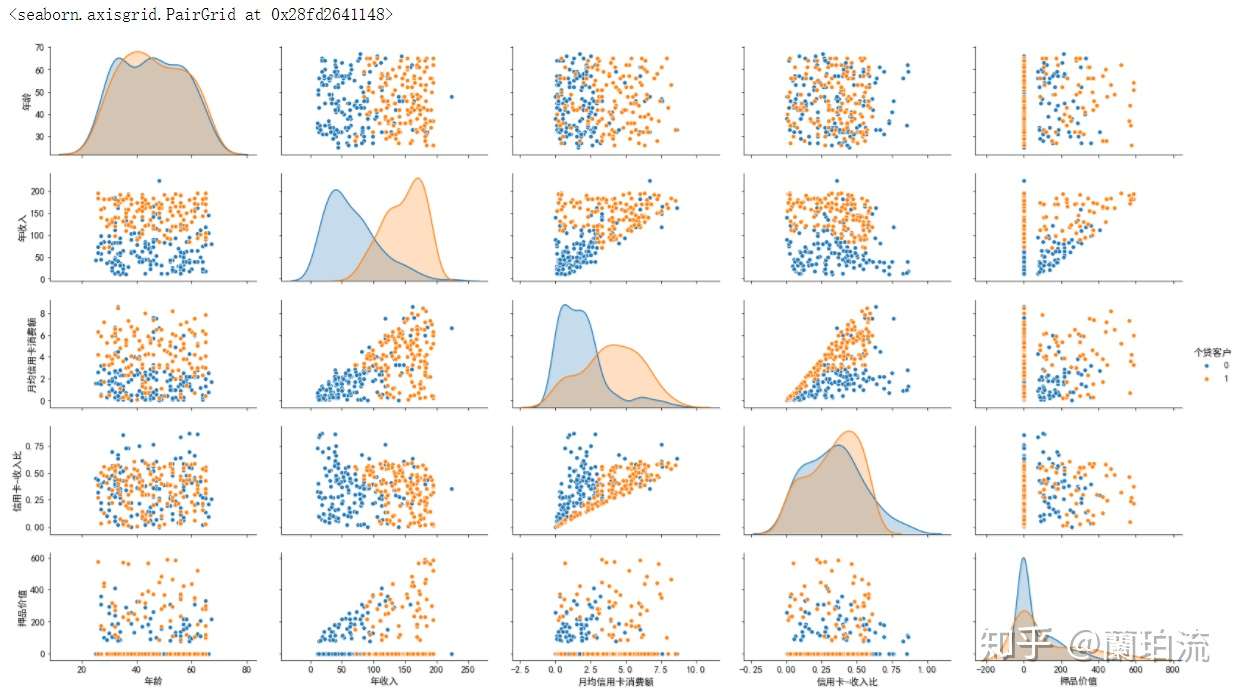
补充:对押品价值的分布进行分箱细化
df['押品价值分箱2']=pd.cut(df.押品价值,10,right=False,precision=0)
bardata_cdloamor=data_cd[data_cd.个贷客户==1].groupby('押品价值分箱').ID.count()
bardata_cdnotloamor=data_cd[data_cd.个贷客户==0].groupby('押品价值分箱').ID.count()
cutbar(bardata_cdnotloamor,bardata_cdloamor,10,'押品价值区间','人数','非个贷客户','个贷客户')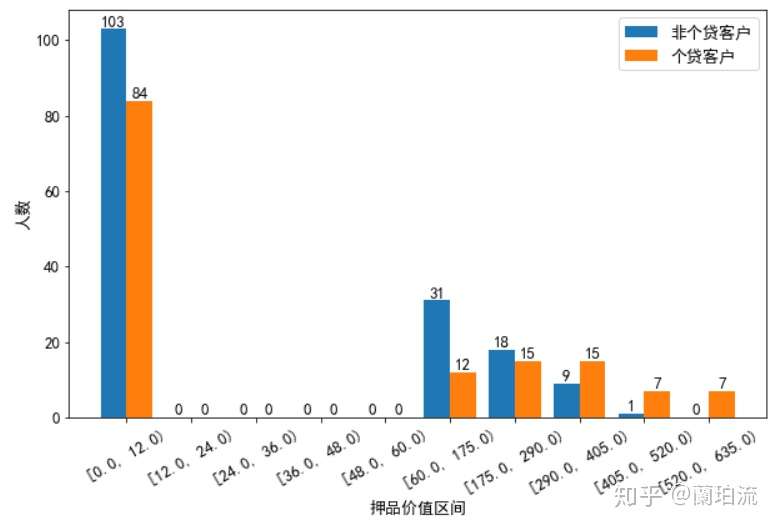
分析:从相关性矩阵散点图可以看出,存款客户中个贷和非个贷客户在年收入和月均信用卡消费额上的区分度比较高,具体来说,年收入在10.2万美元以上且月均信用卡消费额在3千美元以上的存款客户办理个贷业务的倾向非常强;在信用卡收入比方面,在0.65的水平以内二者的区分度不高,但超过0.65的水平后,非个贷的存款客户要多于个贷存款客户;在押品价值方面,存款个贷和存款非个贷客户的押品价值都集中在0值附近,进一步对押品价值分箱处理后发现,存款个贷和存款非个贷客户中绝大多数都没有住房抵押(押品价值为0),同时当押品价值高于40万美元后,存款个贷客户比存款非个贷客户要多。
(2)既存款又个贷的客户与存款但非个贷客户在家庭规模上的分布差异
piedatacd_loa=data_cd.groupby('个贷客户').ID.count()
piedatacd_loafa=data_cd.groupby(['个贷客户','家庭规模(人)']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
sunfig(piedatacd_loa,piedatacd_loafa,0.45,0.5,0.8,1.05)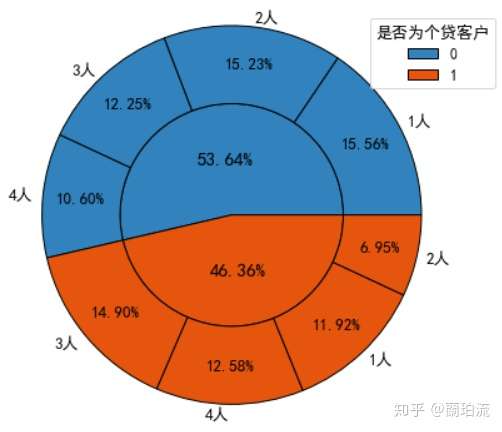
分析:存款非个贷客户以独身或已婚但未育为主,而存款个贷客户以已婚且有子女为主。
(3)既存款又个贷的客户与存款但非个贷客户在文化程度上的分布差异
piedatacd_loaedu=data_cd.groupby(['个贷客户','文化程度2']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
sunfig(piedatacd_loa,piedatacd_loaedu,0.6,0.5,0.8,1.05)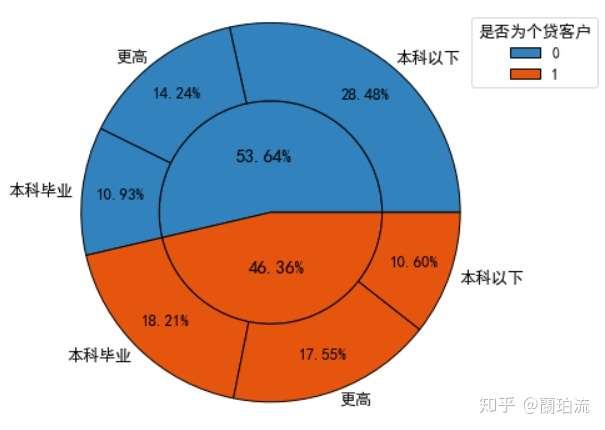
分析:存款非个贷客户的文化程度以本科以下为主,而存款个贷客户的文化程度以本科毕业及以上为主。
六、业务结论及建议
1、结论
1.1客户画像
(1)存款客户画像
1)年龄集中在33到45岁之间,以青中年为主;
2)家庭规模以单身和已婚且有子女为主;
3)年收入分布广泛,集中在4万到16万美元间;
4)信用卡消费以中低水平为主,集中在1千美元左右,但存在部分高消费水平客户;
5)绝大部分没有住房抵押,而有住房抵押的押品价值在6万到17.5万美元的最多。
(2)个贷客户画像
1)年龄集中在32到50岁之间,以青中年为主;
2)文化程度以大学本科及以上为主;
3)家庭规模以已婚且有子女为主;
4)年收入和信用卡消费都以中高水平为主(年收入在9.8万美元以上,月均信用卡消费额在2.8千美元以上);信用卡消费额占其收入比重在30%到40%之间;
5)绝大部分没有住房抵押,而有住房抵押的其押品价值集中在6万到40.5万美元间,且在这一区间内押品价值越高的客户办理个贷业务的倾向越强。
(3)存款客户中的潜在个贷客户画像
1)已婚且有子女;
2)学历在本科及以上;
3)年收入在10.2万美元以上;
4)月均信用卡消费额在3千美元以上;
5)信用卡消费额占其收入比重不超过65%;
6)押品价值高于29万美元。
1.2各类业务间的关联
绝大部分存款客户都会同时办理信用卡或网上银行业务,但同时办理个贷业务的较少,存款客户到个贷客户的转化率不高。
2、建议
(1)存款业务是该行的基础业务,对其他业务具有重要的带动和派生作用;但该次营销活动的受众中只有6.10%的客户在该行开立了存款账户,因而应进一步拓展存款业务的市场份额,扩大存款客户基数。
(2)存款客户中个贷和非个贷客户的区分度非常高,因而应充分利用和盘活存款客户,通过对其加大个贷营销力度、提供个贷优惠等方式促使其向个贷客户转化。
(3)针对绝大部分存款客户使用网上银行的习惯,可以充分利用网上银行作为平台和媒介对存款客户推送个性化的服务,诱导存款客户办理更多的相关业务。
(4)应根据客户画像进行存款和个贷业务的精准营销,以降低营销费用,提高获客效益。
七、对客户是否办理个贷业务进行建模
1、特征工程
(1)先将先前被删除的工作经验为负数的记录补回
df=pd.concat([df,df2],ignore_index=True,sort=False)(2)特征选择:根据前面的相关性分析和探索性分析可知,年收入、月均信用卡消费额、押品价值、家庭规模、文化程度和是否为存款客户这六个特征对客户是否办理个贷业务具有显著影响,因而选取这六个特征训练模型。
(3)特征衍生
1)根据前面的分析,年收入在9.8万美元以上、月均信用卡消费额在2.8千美元以上的客户更有可能是个贷客户,据此生成两个哑变量。
df['年收入大于9.8']=np.where(df.年收入>=9.8,1,0).astype('int')
df['月均信用卡消费额大于2.8']=np.where(df.月均信用卡消费额>=2.8,1,0).astype('int')2)根据前面对存款客户到个贷客户的转化分析,满足年收入在10.2万美元以上、月均信用卡消费额在3千美元以上、押品价值在40万美元、是存款客户这四个条件中的部分或全部条件的客户更有可能是个贷客户,因而可以生成一个综合性变量,对客户满足这四个条件的程度进行赋分,得分越高的客户越有可能是个贷客户。
df['年收入大于102']=np.where(df.年收入>=102,1,0).astype('int')
df['月均信用卡消费额大于3']=np.where(df.月均信用卡消费额>=3,1,0).astype('int')
df['存款到个贷的转化']=df['年收入大于102']+df['月均信用卡消费额大于3']+df.存款客户(4)特征转换
1)改善特征的分布
fig,axes=plt.subplots(1,3,figsize=(10,6))
for i,index in zip(np.arange(3),['年收入','月均信用卡消费额','押品价值']):
df[index].plot(ax=axes[i],kind='box')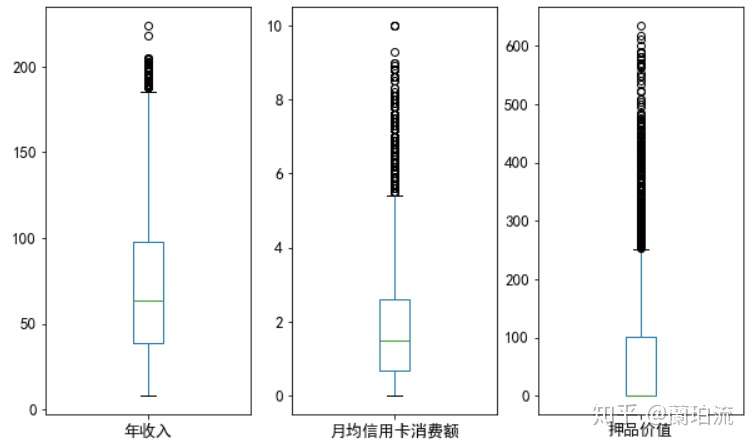
分析:通过箱线图可以看出,年收入、月均信用卡消费额和押品价值这三个字段呈明显的右偏分布,可采用对数变换修正数据倾斜,使其服从类正态分布;但由前面的描述性统计分析可知,押品价值的分布不是连续的,且虽然存在极大值但有住房抵押的客户只占少数,可以预见即使对押品价值进行函数变换也无法得到理想的效果,因而最终只对年收入和月均信用卡消费额进行对数变换,而对押品价值的分布不予处理。
for i in ['年收入_放缩','月均信用卡消费额_放缩']:
df[i]=np.log1p(df[i])2)对年收入、月均信用卡消费额和押品价值三个连续型特征进行标准化处理,消除量纲的影响,同时提高算法求解的收敛速度。
from sklearn import preprocessing as prep
for i in ['年收入_放缩','月均信用卡消费额_放缩','押品价值_放缩']:
df[i]=prep.StandardScaler().fit_transform(df[i].values.reshape(-1,1)) 2、划分输入特征和预测特征,并拆分训练集和测试集
x=np.array(df.loc[:,['年收入_放缩','月均信用卡消费额_放缩','年收入大于9.8','月均信用卡消费额大于2.8','押品价值_放缩',
'家庭规模','文化程度','存款客户','存款到个贷的转化']])
y=np.array(df.个贷客户)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=0)
print('训练集样本量为:',x_train.shape[0],'个')
print('测试集样本量为:',x_test.shape[0],'个')
print('上采样前训练集中正例有%d个,反例有%d个'%((y_train==1).sum(),(y_train==0).sum()))
3、处理类别不平衡:数据集中个贷客户占比只有9.70%,可见存在类别不平衡问题,可采用SMOT算法进行过采样处理。
from imblearn.over_sampling import SMOTE
xtrain,ytrain=SMOTE(random_state=1).fit_sample(x_train,y_train.ravel())
print('SMOTE上采样后,训练集样本量为:',xtrain.shape[0],'个')
print('SMOTE上采样后,样本总量为:',xtrain.shape[0]+x_test.shape[0],'个')
print('SOMTE上采样后,训练集中正例有:',(ytrain==1).sum(),'个')
print('SOMTE上采样后,训练集中反例有:',(ytrain==0).sum(),'个') 
4、建模
(1)导入有关包
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import mean_squared_error,r2_score,precision_score,recall_score,f1_score,accuracy_score,confusion_matrix,roc_curve,auc,roc_auc_score,classification_report(2)定义一个集成建模过程的类
class Modeling():
def __init__(self,alg,params,cvnums):
self.alg=alg
self.name=alg.__class__.__name__
self.params=params
self.cvnums=cvnums
def grid_train_test(self,xtrain,ytrain,x_test,y_test):
grid=GridSearchCV(self.alg,self.params,cv=self.cvnums,scoring='accuracy')
grid.fit(xtrain,ytrain)
self.best_params=grid.best_params_
self.best_estimator=grid.best_estimator_
self.cv_results=grid.cv_results_
self.train_accuracy=grid.best_score_
self.best_estimator.fit(xtrain,ytrain)
self.pred_label=self.best_estimator.predict(x_test)
try:
self.pred_proba=self.best_estimator.decision_function(x_test)
except:
self.pred_proba=self.best_estimator.predict_proba(x_test)[:,1]
self.precision_score=precision_score(y_test,self.pred_label)
self.recall_score=recall_score(y_test,self.pred_label)
self.f1_score=f1_score(y_test,self.pred_label)
self.test_accuracy=accuracy_score(y_test,self.pred_label)
self.auc=round(roc_auc_score(y_test,self.pred_proba),4)
def learningcurve(self,xtrain,ytrain):
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
train_sizes,train_scores,test_scores,fit_times,_=learning_curve(self.alg,xtrain,ytrain,
cv=ShuffleSplit(n_splits=100,test_size=0.2,random_state=2),
return_times=True)
train_scores_mean=np.mean(train_scores,axis=1)
test_scores_mean=np.mean(test_scores,axis=1)
plt.rc('font',size=13)
plt.rcParams['font.sans-serif'] =['SimHei']
fig,axes=plt.subplots(1,2,figsize=(16,4))
axes[0].set_title(self.name)
axes[0].set_xlabel('训练样本数')
axes[0].set_ylabel('准确率')
axes[0].plot(train_sizes,train_scores_mean,'o-',color='r',label='训练集平均准确率')
axes[0].plot(train_sizes,test_scores_mean,'o-',color='g',label='测试集平均准确率')
axes[0].legend(loc='best')
axes[0].grid()
cv_results=pd.DataFrame(self.cv_results)
if len(self.params)==1:
CV_RESULTS=cv_results.pivot_table(values='mean_test_score',index=cv_results.columns[4])
axes[1].set_title(self.name)
axes[1].set_ylabel('准确率')
CV_RESULTS.plot(ax=axes[1],marker='o')
elif len(self.params)==2:
CV_RESULTS=cv_results.pivot_table(values='mean_test_score',index=cv_results.columns[4],columns=cv_results.columns[5])
axes[1].set_title(self.name+'_SCORE')
sns.heatmap(CV_RESULTS,annot=True,ax=axes[1])
else:
heatmap_col=[]
for i in np.arange(len(params)-1):
heatmap_col.append(cv_results.columns[5+i])
CV_RESULTS=cv_results.pivot_table(values='mean_test_score',index=cv_results.columns[4],columns=heatmap_col)
axes[1].set_title(self.name+'_SCORE')
sns.heatmap(CV_RESULTS,annot=True,ax=axes[1])
plt.subplots_adjust(wspace=0.25)(3)选取K近邻分类器、逻辑回归、支持向量机和随机森林分类器这四个模型建模
knn=Modeling(KNeighborsClassifier(),{'n_neighbors':np.linspace(1,10,10).astype('int'),'weights':['uniform','distance']},5)
knn.grid_train_test(xtrain,ytrain,x_test,y_test)
lr=Modeling(LogisticRegression(),{'C':np.linspace(0.6,1.5,10)},5)
lr.grid_train_test(xtrain,ytrain,x_test,y_test)
svm=Modeling(SVC(probability=True),{'C':np.linspace(60,100,5),'gamma':[0.22,0.24,0.26,0.28,0.30]},5)
svm.grid_train_test(xtrain,ytrain,x_test,y_test)
rf=Modeling(RandomForestClassifier(),{'n_estimators':np.linspace(50,200,4).astype('int')},5)
rf.grid_train_test(xtrain,ytrain,x_test,y_test)(4)查看并比较各模型的结果
def resulst_contrast(algclasslist):
algname=[]
best_params=[]
precision_score=[]
recall_score=[]
f1_score=[]
test_accuracy=[]
auc=[]
for alg in algclasslist:
algname.append(alg.name)
best_params.append(alg.best_params)
precision_score.append(alg.precision_score)
recall_score.append(alg.recall_score)
f1_score.append(alg.f1_score)
test_accuracy.append(alg.test_accuracy)
auc.append(round(alg.auc,4))
return pd.DataFrame({'模型':algname,'最优参数':best_params,'查准率':precision_score,'查全率':recall_score,'f1得分':f1_score,
'测试集正确率':test_accuracy,'auc':auc}).set_index('模型').sort_values(by='auc',ascending=False)
resulst_contrast([knn,lr,svm,rf])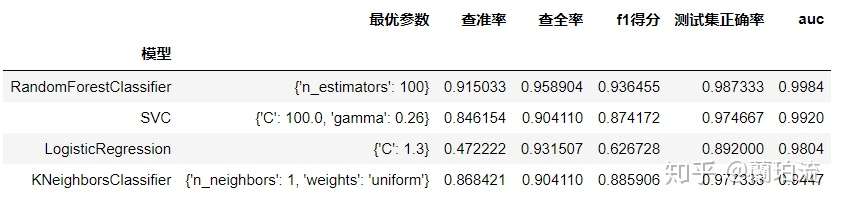
分析:可以看出,逻辑回归、支持向量机和随机森林分类器的auc都达到了0.95以上,但其中逻辑回归的查准率和预测正确率不够理想,不过这并不妨碍该模型的使用价值,因为本业务是要尽可能多得识别出潜在的个贷客户,因而相比于查准率本业务更看重查全率;而k近邻分类器虽然auc低于0.95,但其预测正确率并不低;所有模型中预测性能最好的是随机森林分类器,其f1得分和预测正确率都很高,且auc高达0.9984。
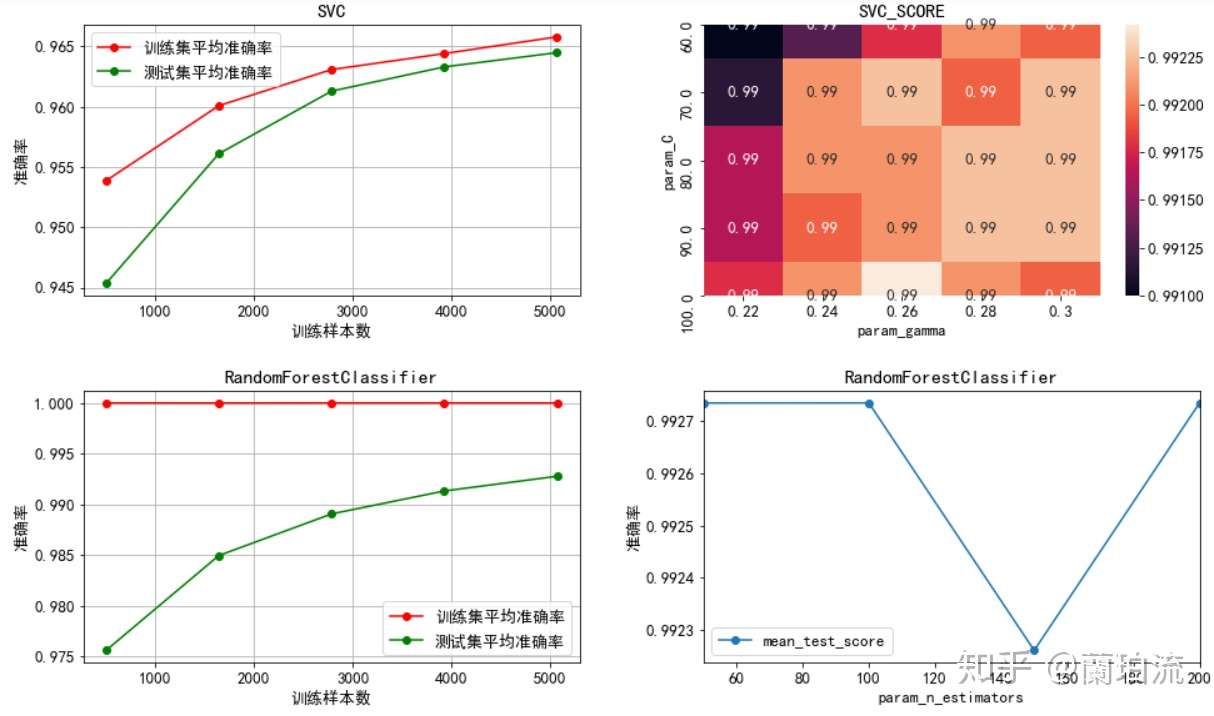
(5)绘制各模型的学习曲线
knn.learningcurve(xtrain,ytrain)
lr.learningcurve(xtrain,ytrain)
svm.learningcurve(xtrain,ytrain)
rf.learningcurve(xtrain,ytrain)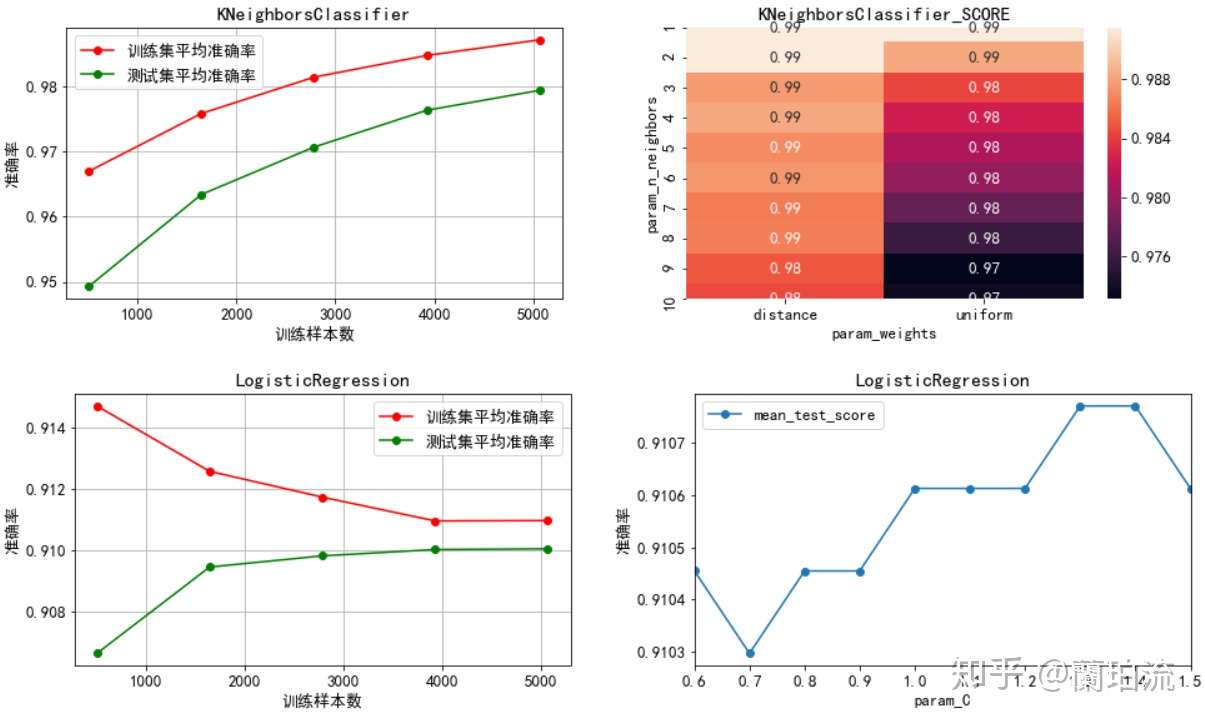
分析:
1)通过左半部分的学习曲线可以看出,在交叉验证过程中除了逻辑回归以外其余三个模型的训练集准确率都处于较高水平,尤其是随机森林模型的准确率一直维持在100%,因而可能存在一定程度的过拟合问题,推测这种过拟合主要是因为在处理类别不均衡问题时进行了过采样造成的;而逻辑回归的训练集准确率随着样本量的增加不断降低,可能存在一定程度的欠拟合问题,推测主要是因为逻辑回归模型不能很好地处理非线性可分问题,从而导致模型的学习难度随着样本量的不断增加而增大,最终造成欠拟合问题。
2)K近邻:最优近邻数为1,且通过热力图可以看出模型准确率随着近邻数的增加而下降,因而不需要再进行调参。
3)逻辑回归:最优正则化系数的倒数为1.3,且通过学习曲线可以看出模型准确率在正则化系数倒数为1.3处取到最值,因而不需要再进行调参。
4)支持向量机:通过热力图可以看出,矩阵中最优系数搭配组合(误分类惩罚系数100,核函数系数0.26)周围看不出明显的能使模型准确率提升的参数变化趋势,因而不再进一步调参。
5)随机森林分类器:最优决策树个数为100,且通过学习曲线可以看出决策树个数向100两侧变化并不能带来模型准确率的提高,因而不再进一步调参。
(6)模型融合:选取预测性能前三的逻辑回归、支持向量机和随机森林分类器采用投票评估器进行融合。
from sklearn.ensemble import VotingClassifier
ensemble_voting=VotingClassifier(estimators=[('lr',lr.best_estimator),('svm',svm.best_estimator),('rf',rf.best_estimator)],voting='soft')
ensemble_voting.fit(xtrain,ytrain)
auc=roc_auc_score(y_test,ensemble_voting.predict_proba(x_test)[:,1])
print('VotingClassifier的auc为:%.4f'%(auc))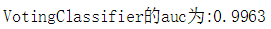
分析:可以看出,融合后的auc没有单个模型的auc高,因而采用随机森林分类器作为最终模型。
(7)输出最优分类器
rf.best_estimator
内容概要
●首先,对某银行某次营销活动受众客户的特征进行了描述性统计,考察了营销活动的总体效果;同时还进行了特征间的相关性分析,筛掉了与响应行为之间没有显著相关性的特征;
●其次,分别考察了存款和个贷客户在年龄、年收入等6个特征上的分布情况,分析了存款和个贷客户的自然属性和消费行为特征,并据此构建了存款客户画像和个贷客户画像;
●然后,运用Apriori关联规则算法分析了各类业务之间的关联,并重点总结出了存款客户中潜在个贷客户的特征;
●接着,根据以上分析结果尝试为该银行扩大各类业务客户基数,提高获客能力提出建议;
●最后,根据分析出的个贷客户画像对客户是否办理个贷业务进行建模,得出最优分类器;当有新的客户数据时便可以使用该模型对客户办理个贷业务的可能性进行预测。
关键词
●python
●客户画像
●二分类
●关联分析
内容大纲
一、项目描述
1、项目说明
(1)数据来源:本项目所用数据来源于kaggle平台,该数据集展示了某银行某年一次贷款营销活动的5,000条客户信息记录。
(2)使用工具:本项目的分析和可视化都是使用python完成的,但相关性分析用到了SPSS。
(3)数据描述:数据字典如下表所示:
表1 数据字典
2、业务需求
2.1业务背景
某银行是一家客户群不断增长的银行,但其贷款业务的客户基数较小,因此该行希望能够将存款用户转化为贷款用户,扩大贷款业务量,从而赚取更多的存贷利差。为此,该行零售信贷部于2016年针对部分客户开展了一次推广个人贷款业务的营销活动,并希望通过数据分析识别出办理个贷业务的潜在客户。
2.2提出问题
(1)该次营销活动的受众客户中有多少办理了该行的有关业务,各类业务的获客情况如何。
(2)办理了存款和个贷业务的客户分别具备什么样的共性特征。
(3)存款客户到个贷客户的转化率有多少,具备怎样特征的存款客户能够有效转化成个贷客户。
(4)根据个贷客户画像对客户是否办理个贷业务进行建模。
二、数据清洗与预处理
导入库并预览数据
import numpy as np,pandas as pd,matplotlib.pyplot as plt,seaborn as sns
url='C:/Users/lelelan/Desktop/Exercises and Projects/dataset/credit/Bank_Personal_Loan_Modelling.xlsx'
df=pd.read_excel(url,sheet_name='Data')
df.head(5)查看字段名的规范性
df.columns修改字段名为中文名
df.columns=['ID','年龄','工作经验','年收入','邮编','家庭规模','月均信用卡消费额','文化程度',
'押品价值','个贷客户','证券客户','存款客户','网上银行','信用卡客户']去掉金额字段的单位符号
for x in ['年收入','月均信用卡消费额','押品价值']:df[x]=df[x].str[:-2] 查看各字段类型
df.dtypes修正ID、年收入、月均信用卡消费额和押品价值四个字段的类型
df['ID']=df.ID.astype('object')
for x in ['年收入','押品价值']:df[x]=df[x].astype('int64')
df.月均信用卡消费额=round(df.月均信用卡消费额.astype('float64'),2)删除邮编字段
df.drop('邮编',axis=1,inplace=True)删除重复记录
df.drop_duplicates(inplace=True)
df[df.duplicated()].ID.count()对数值型字段进行描述性统计,并查看异常值
df.describe().T分析:
(1)连续型特征:年龄和工作经验的均值与中位数比较相近,说明二者分布比较均匀,但它们的标准差不低,说明年龄和工作经验的分布比较广;年收入、月均信用卡消费额和押品价值的均值都比中位数高,说明它们都呈右偏分布,存在极大值;其中年收入和押品价值的标准差非常大,右偏程度很高;尤其是押品价值的中位数为0,可见50%以上的客户没有住房抵押。
(2)类别型特征:从5个二分类字段的均值可以得出,办理了信用卡业务的客户数占抽样所得客户总数的比例约为29.40%;办理了证券业务的客户占比约为10.44%;办理了个贷业务的客户占比约为9.60%;办理了存款业务的客户占比约为6.04%;使用网上银行的客户占比约为59.68%。
先将工作经验字段为负数的记录另存并删除,便于接下来的描述性统计分析
df2=df.loc[df.工作经验<0]
df.drop(df2.index,inplace=True)
df.loc[df.工作经验<0,'ID'].count()查看各字段的缺失值数量
df.isnull().sum()可见不存在缺失值
三、特征总体分析
1、分类型特征
1.1描述性统计:频数和比例
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rc('font',size=13)
width=0.4
fig,axes=plt.subplots(2,4,sharey=True,figsize=(15,10))
def pltbar(m,n,index,unit):
data=df.groupby(index).ID.count()
ratiodata=data/df.ID.count()
x=np.arange(len(data))
axes[m,n].set_xticks(x)
axes[m,n].set_ylabel('人数')
axes[m,n].bar(x-width/2,data,width=width)
for a,b in zip(x-width/2-0.08,data):
axes[m,n].text(a,b,b,ha='center',va='bottom',color='k')
axes[m,n].set_xticklabels(data.index)
axes[m,n].set_xlabel(index+unit)
axes2=axes[m,n].twinx()
axes2.bar(x+width/2,ratiodata,width=width,label='比例',color='#f97306')
for a,b in zip(x+width/2,ratiodata):
axes2.text(a,b,'%.2f%%'%(b*100),ha='center',va='bottom',color='k')
axes2.legend(loc='best')
plt.subplots_adjust(wspace=0.3)
pltbar(0,0,'家庭规模','(人)')
pltbar(0,1,'文化程度','')
pltbar(0,2,'个贷客户','')
pltbar(0,3,'证券客户','')
pltbar(1,0,'存款客户','')
pltbar(1,1,'网上银行','')
pltbar(1,2,'信用卡客户','')分析:
(1)家庭规模方面:家庭规模为1人,即单身的客户最多;客户次多的家庭规模从高到低依次是2人、4人和3人;但这4种家庭规模的客户数量彼此差异不大,占客户总数的比例都在20%到30%之间,分布较为均匀。
(2)文化程度方面:本科学历以下的客户最多,但文化程度在本科毕业及以上的客户数合计占比超过了一半,可见该行客户以受过大学本科教育的客户为主。
(3)响应行为方面:未办理个贷、证券、存款和信用卡业务的客户要远多于办理了相应业务的客户,可见该次营销活动的受众中只有很少一部分办理过该行的有关业务。
1.2相关性分析
(1)通过SPSS借助皮尔逊卡方独立性检验对各分类型字段之间的相关性进行分析,得到检验结果的显著性水平如下表
表2 分类型特征的皮尔逊卡方独立性检验
(2)通过卡方独立性检验可以得出,文化程度与是否为存款客户之间没有显著相关性;是否为证券客户、是否为信用卡客户、是否使用网上银行与是否为个贷客户之间没有显著相关性,是否为证券客户与是否为信用卡客户、家庭规模、文化程度和是否使用网上银行间没有显著相关性;是否为信用卡客户与家庭规模、文化程度、网上银行之间没有显著相关性。
(3)基于卡方独立性检验的结果,在分析客户画像时将不考虑与响应行为之间没有显著相关性的特征,即在分析存款客户画像时,将不考虑“文化程度”特征;在分析个贷客户画像时,将不考虑“证券客户”、“信用卡客户”和“网上银行”这三个特征。
2、连续型特征:数值分布与相关性分析
2.1矩阵散点图
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rc('font',size=13)
sns.pairplot(df.loc[:,['年龄','工作经验','年收入','月均信用卡消费额','押品价值']],diag_kind='kde',aspect=1.8)2.2皮尔逊相关系数矩阵
通过SPSS借助因子分析得到各连续型特征之间的皮尔逊相关系数,如下表所示
表3 连续型特征的皮尔逊相关系数矩阵
分析:
(1)数值分布分析:该行客户总体上年龄集中在30岁到60岁之间,但36和46岁的客户要比相邻年龄的客户少一些;工龄集中在7到34年;年收入集中在4万到7.5万美元间;月均信用卡消费额集中在0.5到2千美元间;押品价值集中在0值上,说明绝大部分客户没有住房抵押,但押品价值的核密度在10万美元处有一个极值,说明有住房抵押的客户大部分押品价值都在10万美元左右。
(2)相关性分析:由相关性矩阵和散点图可以看出,年龄与年收入(r=-0.058,p=0.000<0.05)以及月均信用卡消费额(r=-0.053,p=0.000<0.05)之间的相关性较弱;工作经验与年龄具有高度的正相关性(r=0.994,p=0.000<0.05),而与年收入(r=-0.049,p=0.000<0.05)和月均信用卡消费额。(r=-0.051,p=0.000<0.05)之间的相关性较弱;年收入越高,月均信用卡消费额(r=0.639,p=0.000<0.05)和押品价值(r=0.207,p=0.000<0.05)的上限越高。
四、存贷款业务客户画像
1、存款客户画像
1.1存款和非存款客户在年龄、年收入、月均信用卡消费额和押品价值上的分布差异
def multi_kde(data,pointsnum,unit):
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rc('font',size=13)
i=data.shape[1]
a=data.columns.values[0]
fig,axes=plt.subplots(1,i-1,figsize=(20,5))
for j,k in zip(np.arange(1,i),np.arange(i-1)):
b=data[data[a]==0]
c=data[data[a]==1]
d=data.iloc[:,j]
e=np.array(unit)
plt.xticks(np.arange(d.min(),d.max(),int((d.max()-d.min())/pointsnum)))
axes[k].set_xlabel(data.columns.values[j]+e[k])
b.iloc[:,j].plot.kde(ax=axes[k])
c.iloc[:,j].plot.kde(ax=axes[k])
axes[k].legend(labels=['非'+a,a],loc='best',fontsize=10)
plt.subplots_adjust(wspace=0.3)
multi_kde(df.loc[:,['存款客户','年龄','年收入','月均信用卡消费额','押品价值']],5,['','(k$)','(k$)','(k$)'])补充:对押品价值进行分箱分析
def cutbar(data1,data2,num,xlabel,ylabel,data1label,data2label):
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rc('font',size=13)
fig,axes=plt.subplots(1,1,sharey=True,figsize=(10,6))
axes.set_xlabel('押品价值区间')
axes.set_ylabel('人数')
width=0.4
x=np.arange(num)
axes.set_xticks(x)
axes.bar(x-width/2,data1,width=width,label=data1label)
axes.bar(x+width/2,data2,width=width,label=data2label)
axes.legend(loc='best')
axes.set_xticklabels(data1.index.values,rotation=30)
for a,b in zip(x-width/2,data1):
axes.text(a,b,b,ha='center',va='bottom',color='k')
for a,b in zip(x+width/2,data2):
axes.text(a,b,b,ha='center',va='bottom',color='k')
a=sorted(list(set(np.concatenate([np.linspace(0,60,6),np.linspace(60,df.押品价值.max(),6)],axis=0))))
df['押品价值分箱']=pd.cut(df.押品价值,a,right=False,precision=0)
bardata_cdmor=df[df.存款客户==1].groupby('押品价值分箱').ID.count()
bardata_notcdmor=df[df.存款客户==0].groupby('押品价值分箱').ID.count()
cutbar(bardata_notcdmor,bardata_cdmor,10,'押品价值区间','人数','非存款客户','存款客户')分析:
(1)在年龄的分布上:存款客户的年龄集中在33到55岁之间,这其中年龄在33岁到45岁之间的客户要多于其他年龄段的客户,可见存款客户以青中年为主。
(2)在年收入的分布上:非存款客户的年收入呈右偏分布,但整体集中在4万美元左右,说明非存款客户以中低收入为主;而存款客户的年收入分布相对广泛且均匀,集中在4万到16万美元之间。
(3)在月均信用卡消费额的分布上:存款和非存款客户的月均信用卡消费额都集中在1千美元左右,可见两类客户信用卡消费水平整体都不高;但存款客户的月均信用卡消费额呈右偏分布,存在高消费水平的客户。
(4)在押品价值的分布上:存款和非存款客户的押品价值都集中在0值附近,进一步对押品价值分箱处理后发现,存款和非存款客户中绝大多数都没有住房抵押(押品价值为0),而有住房抵押的存款客户其押品价值在6万到17.5万美元间的最多,有住房抵押的非存款客户其押品价值在10万美元左右的最多(其核密度曲线在10万美元处有一极值),同时随着押品价值的升高存款和非存款客户的数量都越来越少。
1.2存款和非存款客户在家庭规模上的分布差异
piedata_cd=df.groupby('存款客户').ID.count()
df['家庭规模(人)']=df.家庭规模.apply(lambda x:'%d人'%(x))
piedata_cdfam=df.groupby(['存款客户','家庭规模(人)']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
def sunfig(data_level1,data_level2,bbox_to_anchor_left,pctdistance1,pctdistance2,labeldistance):
plt.rcParams['font.sans-serif'] =['SimHei']
plt.figure(figsize=(6,6))
cmap=plt.get_cmap("tab20c")
points=np.arange(len(data_level2.index.levels[0]))*4
inner_colors=cmap(points)
outer_colors=cmap(points.repeat([len(data_level2[0]),len(data_level2[1])]))
wedges,texts,autotexts=plt.pie(data_level1.values,radius=1,autopct='%1.2f%%',pctdistance=pctdistance1,
textprops={'fontsize':15},colors=inner_colors,wedgeprops=dict(width=1,edgecolor='k'))
plt.legend(wedges,title="是否为%s"%(data_level2.index.get_level_values(0).name),labels=data_level1.index.get_level_values(0),fontsize=12,
bbox_to_anchor=(bbox_to_anchor_left,0,0.7,1))
plt.pie(data_level2.values,radius=1+0.7,autopct='%1.2f%%',labels=data_level2.index.get_level_values(1),
pctdistance=pctdistance2,labeldistance=labeldistance,
textprops={'fontsize':13},colors=outer_colors,wedgeprops=dict(width=0.7,edgecolor='k'))
plt.axis('equal')
sunfig(piedata_cd,piedata_cdfam,0.45,0.5,0.8,1.05)分析:家庭规模为1人,即处于单身或离异状态的客户在存款和非存款客户中的占比都是最大的;但在存款客户中家庭规模为3人和4人,即已婚且有子女的客户占比要高于家庭规模为2人即已婚但未育的客户。
2、个贷客户画像
2.1个贷和非个贷客户在年龄、年收入、月均信用卡消费额和押品价值上的分布差异
multi_kde(df.loc[:,['个贷客户','年龄','年收入','月均信用卡消费额','押品价值']],5,['','(k$)','(k$)','(k$)'])补充:对押品价值进行分箱分析
df['押品价值分箱']=pd.cut(df.押品价值,a,right=False,precision=0)
bardata_loamor=df[df.个贷客户==1].groupby('押品价值分箱').ID.count()
bardata_notloamor=df[df.个贷客户==0].groupby('押品价值分箱').ID.count()
cutbar(bardata_notloamor,bardata_loamor,10,'押品价值区间','人数','非个贷客户','个贷客户')分析:
(1)在年龄的分布上:个贷客户的年龄主要集中在32岁到50岁之间,这其中32到38岁的客户要多于其他年龄段的客户,同时40岁左右的客户要比相邻年龄的客户少。
(2)在年收入的分布上:非个贷客户年收入呈右偏分布,但集中在4万到8万美元左右,以中低收入为主;而个贷客户的年收入分布相对均匀,集中在13万美元到17.5万美元间,以中高收入为主;同时在9.8万美元右侧,个贷客户的核密度曲线呈急剧上升,而非个贷客户的核密度曲线在急剧下降,可见年收入9.8万美元是个分界点,年收入高于该水平的客户更有可能办理个贷业务。
(3)在月均信用卡消费额的分布上:非个贷客户的月均信用卡消费额呈右偏分布,但集中在0.5到1.7千美元之间,消费水平整体偏低;而个贷客户的月均信用卡消费额分布相对均匀,并集中在3.5千美元左右,以中高消费水平为主。同时在2.8千美元右侧,个贷客户的核密度曲线呈急剧上升并很快达到峰值,而非个贷客户的核密度曲线呈急剧下降,可见2.8千美元是一个分界点,月均信用卡消费额高于该水平的客户更有可能办理个贷业务。
(4)在押品价值的分布上:个贷和非个贷客户的押品价值都集中在0值附近,进一步对押品价值分箱处理后发现,个贷和非个贷客户中绝大多数都没有住房抵押(押品价值为0),且个贷客户中有住房抵押的其押品价值在29万到40.5万美元间的最多,并且当押品价值在6万到40.5万美元之间时,随着押品价值的升高个贷客户的数量在增多,而非个贷客户的数量在减少。
2.2个贷和非个贷客户在信用卡还款压力上的分布差异
计算年信用卡消费额占年均收入的比重可以得出客户对信用卡的使用程度,也能反映客户信用卡的还款压力
df['信用卡-收入比']=round(df.月均信用卡消费额*12/df.年收入,3)
plt.rcParams['font.sans-serif'] =['SimHei']
plt.figure(figsize=(8,6))
plt.xlabel('信用卡-收入比')
plt.xticks(np.arange(df['信用卡-收入比'].min(),df['信用卡-收入比'].max(),
round((df['信用卡-收入比'].max()-df['信用卡-收入比'].min())/10,1)))
df.loc[df.个贷客户==0,'信用卡-收入比'].plot.kde(label='非个贷客户')
df.loc[df.个贷客户==1,'信用卡-收入比'].plot.kde(label='个贷客户')
plt.legend(loc='upper right',fontsize=10)
plt.ylabel('核密度')分析:非个贷客户的信用卡消费额占其收入的比重集中在20%左右,而个贷客户的信用卡消费额占其收入的比重集中在40%左右;同时,在20%到40%这一区间内,非个贷客户的核密度曲线急剧下降,而个贷客户的核密度曲线急剧上升并达到峰值,可见信用卡-收入比在30%到40%之间的客户办理个贷业务的倾向最强。但当信用卡消费额占收入的比重超过65%以后,个贷客户数量的下降幅度要大于非个贷客户,可见虽然大部分非个贷客户对信用卡的使用较为保守,但也存在小部分不理性使用信用卡的客户。
2.3个贷和非个贷客户在家庭规模上的分布差异
piedata_loa=df.groupby('个贷客户').ID.count()
piedata_loafa=df.groupby(['个贷客户','家庭规模(人)']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
sunfig(piedata_loa,piedata_loafa,0.5,0.5,0.8,1.05)分析:非个贷客户以独身或已婚未育为主,而个贷客户则以已婚有子女为主。
2.4个贷和非个贷客户在文化程度上的分布差异
def wenhua(x):
if x==1:
return '本科以下'
elif x==2:
return '本科毕业'
else:
return '更高'
df['文化程度2']=df.文化程度.apply(lambda x:wenhua(x))
piedata_loaedu=df.groupby(['个贷客户','文化程度2']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
sunfig(piedata_loa,piedata_loaedu,0.47,0.5,0.8,1.05)分析:文化程度在本科以下的客户在非个贷客户中的占比最高,达到了44.31%(40.06%/90.04%),而在个贷客户中的占比最低,仅为19.37%(1.86%/9.60%),个贷客户中本科毕业及以上学历的客户合计约占其80.63%((3.64%+4.10%)/9.60%),可见受过大学本科教育的客户办理个贷业务的意识更强。
五、各响应行为间的关联分析
1、各类业务间的Apriori关联分析
#导入Apriori关联规则算法包
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules(1)设定最小支持度为0.04,挖掘频繁项集
frequent_itemsets=apriori(df.iloc[:,-5:],min_support=0.04,use_colnames=True).sort_values('support',ascending=False)
frequent_itemsets分析:通过上表可知,该行同时办理信用卡和网上银行业务的客户占比约为17.74%;同时办理证券和网上银行业务的客户占比约为6.47%;同时办理个贷和网上银行业务的客户占比约为5.88%;同时办理存款和网上银行业务的客户占比约为5.72%;同时办理存款和信用卡业务的客户占比约为4.85%;同时办理存款、信用卡和网上银行业务的客户占比约为4.53%。
(2)设定最小置信度为0.7,挖掘强关联规则
rules=association_rules(frequent_itemsets,metric='confidence',min_threshold=0.7).sort_values('confidence',ascending=False)
rules分析:
1)通过上表可知,客户如果办理了存款业务,那么就有93.71%的概率会开通网上银行,有79.47%的概率会办理信用卡业务,有74.17%的概率会同时办理信用卡和网上银行业务;客户如果同时办理了存款和信用卡业务,那么就有93.33%的概率会开通网上银行;客户如果同时办理了存款和网上银行业务,那么就有79.15%的概率会办理信用卡业务。
2)通过以上分析可以看出,绝大部分存款客户都会同时办理信用卡或网上银行业务,可见存款业务对这两个业务具有很好的衍生作用,但并未看到存款业务对个贷业务的衍生作用,可见该行并没有把存款客户有效地转化为个贷客户。
(3)查看存款客户中个贷客户的比例
df['是否个贷']=df.个贷客户.apply(lambda x:'个贷客户' if x==1 else '非个贷客户')
piedata_cdloa=df.groupby(['存款客户','是否个贷']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
sunfig(piedata_cd,piedata_cdloa,0.46,0.5,0.8,1.05)分析:存款客户中办理了个贷业务的客户占比,即该次营销活动的转化率为46.39%(2.83%/6.10%),可见超过一半的存款客户并没有办理个贷业务,因而需要挖掘存款客户中潜在个贷客户的特征,针对这部分客户进行个贷业务的精准营销,以提高存款到个贷客户的转化率。
2、存款客户中的潜在个贷客户特征
(1)既存款又个贷的客户与存款但非个贷客户在年龄、年收入、信用卡消费水平以及押品价值方面的差异
data_cd=df[df.存款客户==1]
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rc('font',size=13)
sns.pairplot(data_cd.loc[:,['个贷客户','年龄','年收入','月均信用卡消费额','信用卡-收入比','押品价值']],
vars=['年龄','年收入','月均信用卡消费额','信用卡-收入比','押品价值'],hue='个贷客户',diag_kind='kde',aspect=1.8)补充:对押品价值的分布进行分箱细化
df['押品价值分箱2']=pd.cut(df.押品价值,10,right=False,precision=0)
bardata_cdloamor=data_cd[data_cd.个贷客户==1].groupby('押品价值分箱').ID.count()
bardata_cdnotloamor=data_cd[data_cd.个贷客户==0].groupby('押品价值分箱').ID.count()
cutbar(bardata_cdnotloamor,bardata_cdloamor,10,'押品价值区间','人数','非个贷客户','个贷客户')分析:从相关性矩阵散点图可以看出,存款客户中个贷和非个贷客户在年收入和月均信用卡消费额上的区分度比较高,具体来说,年收入在10.2万美元以上且月均信用卡消费额在3千美元以上的存款客户办理个贷业务的倾向非常强;在信用卡收入比方面,在0.65的水平以内二者的区分度不高,但超过0.65的水平后,非个贷的存款客户要多于个贷存款客户;在押品价值方面,存款个贷和存款非个贷客户的押品价值都集中在0值附近,进一步对押品价值分箱处理后发现,存款个贷和存款非个贷客户中绝大多数都没有住房抵押(押品价值为0),同时当押品价值高于40万美元后,存款个贷客户比存款非个贷客户要多。
(2)既存款又个贷的客户与存款但非个贷客户在家庭规模上的分布差异
piedatacd_loa=data_cd.groupby('个贷客户').ID.count()
piedatacd_loafa=data_cd.groupby(['个贷客户','家庭规模(人)']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
sunfig(piedatacd_loa,piedatacd_loafa,0.45,0.5,0.8,1.05)分析:存款非个贷客户以独身或已婚但未育为主,而存款个贷客户以已婚且有子女为主。
(3)既存款又个贷的客户与存款但非个贷客户在文化程度上的分布差异
piedatacd_loaedu=data_cd.groupby(['个贷客户','文化程度2']).ID.count().groupby(level=0,group_keys=False).nlargest(10)
sunfig(piedatacd_loa,piedatacd_loaedu,0.6,0.5,0.8,1.05)分析:存款非个贷客户的文化程度以本科以下为主,而存款个贷客户的文化程度以本科毕业及以上为主。
六、业务结论及建议
1、结论
1.1客户画像
(1)存款客户画像
1)年龄集中在33到45岁之间,以青中年为主;
2)家庭规模以单身和已婚且有子女为主;
3)年收入分布广泛,集中在4万到16万美元间;
4)信用卡消费以中低水平为主,集中在1千美元左右,但存在部分高消费水平客户;
5)绝大部分没有住房抵押,而有住房抵押的押品价值在6万到17.5万美元的最多。
(2)个贷客户画像
1)年龄集中在32到50岁之间,以青中年为主;
2)文化程度以大学本科及以上为主;
3)家庭规模以已婚且有子女为主;
4)年收入和信用卡消费都以中高水平为主(年收入在9.8万美元以上,月均信用卡消费额在2.8千美元以上);信用卡消费额占其收入比重在30%到40%之间;
5)绝大部分没有住房抵押,而有住房抵押的其押品价值集中在6万到40.5万美元间,且在这一区间内押品价值越高的客户办理个贷业务的倾向越强。
(3)存款客户中的潜在个贷客户画像
1)已婚且有子女;
2)学历在本科及以上;
3)年收入在10.2万美元以上;
4)月均信用卡消费额在3千美元以上;
5)信用卡消费额占其收入比重不超过65%;
6)押品价值高于29万美元。
1.2各类业务间的关联
绝大部分存款客户都会同时办理信用卡或网上银行业务,但同时办理个贷业务的较少,存款客户到个贷客户的转化率不高。
2、建议
(1)存款业务是该行的基础业务,对其他业务具有重要的带动和派生作用;但该次营销活动的受众中只有6.10%的客户在该行开立了存款账户,因而应进一步拓展存款业务的市场份额,扩大存款客户基数。
(2)存款客户中个贷和非个贷客户的区分度非常高,因而应充分利用和盘活存款客户,通过对其加大个贷营销力度、提供个贷优惠等方式促使其向个贷客户转化。
(3)针对绝大部分存款客户使用网上银行的习惯,可以充分利用网上银行作为平台和媒介对存款客户推送个性化的服务,诱导存款客户办理更多的相关业务。
(4)应根据客户画像进行存款和个贷业务的精准营销,以降低营销费用,提高获客效益。
七、对客户是否办理个贷业务进行建模
1、特征工程
(1)先将先前被删除的工作经验为负数的记录补回
df=pd.concat([df,df2],ignore_index=True,sort=False)(2)特征选择:根据前面的相关性分析和探索性分析可知,年收入、月均信用卡消费额、押品价值、家庭规模、文化程度和是否为存款客户这六个特征对客户是否办理个贷业务具有显著影响,因而选取这六个特征训练模型。
(3)特征衍生
1)根据前面的分析,年收入在9.8万美元以上、月均信用卡消费额在2.8千美元以上的客户更有可能是个贷客户,据此生成两个哑变量。
df['年收入大于9.8']=np.where(df.年收入>=9.8,1,0).astype('int')
df['月均信用卡消费额大于2.8']=np.where(df.月均信用卡消费额>=2.8,1,0).astype('int')2)根据前面对存款客户到个贷客户的转化分析,满足年收入在10.2万美元以上、月均信用卡消费额在3千美元以上、押品价值在40万美元、是存款客户这四个条件中的部分或全部条件的客户更有可能是个贷客户,因而可以生成一个综合性变量,对客户满足这四个条件的程度进行赋分,得分越高的客户越有可能是个贷客户。
df['年收入大于102']=np.where(df.年收入>=102,1,0).astype('int')
df['月均信用卡消费额大于3']=np.where(df.月均信用卡消费额>=3,1,0).astype('int')
df['存款到个贷的转化']=df['年收入大于102']+df['月均信用卡消费额大于3']+df.存款客户(4)特征转换
1)改善特征的分布
fig,axes=plt.subplots(1,3,figsize=(10,6))
for i,index in zip(np.arange(3),['年收入','月均信用卡消费额','押品价值']):
df[index].plot(ax=axes[i],kind='box')分析:通过箱线图可以看出,年收入、月均信用卡消费额和押品价值这三个字段呈明显的右偏分布,可采用对数变换修正数据倾斜,使其服从类正态分布;但由前面的描述性统计分析可知,押品价值的分布不是连续的,且虽然存在极大值但有住房抵押的客户只占少数,可以预见即使对押品价值进行函数变换也无法得到理想的效果,因而最终只对年收入和月均信用卡消费额进行对数变换,而对押品价值的分布不予处理。
for i in ['年收入_放缩','月均信用卡消费额_放缩']:
df[i]=np.log1p(df[i])2)对年收入、月均信用卡消费额和押品价值三个连续型特征进行标准化处理,消除量纲的影响,同时提高算法求解的收敛速度。
from sklearn import preprocessing as prep
for i in ['年收入_放缩','月均信用卡消费额_放缩','押品价值_放缩']:
df[i]=prep.StandardScaler().fit_transform(df[i].values.reshape(-1,1)) 2、划分输入特征和预测特征,并拆分训练集和测试集
x=np.array(df.loc[:,['年收入_放缩','月均信用卡消费额_放缩','年收入大于9.8','月均信用卡消费额大于2.8','押品价值_放缩',
'家庭规模','文化程度','存款客户','存款到个贷的转化']])
y=np.array(df.个贷客户)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=0)
print('训练集样本量为:',x_train.shape[0],'个')
print('测试集样本量为:',x_test.shape[0],'个')
print('上采样前训练集中正例有%d个,反例有%d个'%((y_train==1).sum(),(y_train==0).sum()))3、处理类别不平衡:数据集中个贷客户占比只有9.70%,可见存在类别不平衡问题,可采用SMOT算法进行过采样处理。
from imblearn.over_sampling import SMOTE
xtrain,ytrain=SMOTE(random_state=1).fit_sample(x_train,y_train.ravel())
print('SMOTE上采样后,训练集样本量为:',xtrain.shape[0],'个')
print('SMOTE上采样后,样本总量为:',xtrain.shape[0]+x_test.shape[0],'个')
print('SOMTE上采样后,训练集中正例有:',(ytrain==1).sum(),'个')
print('SOMTE上采样后,训练集中反例有:',(ytrain==0).sum(),'个') 4、建模
(1)导入有关包
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import mean_squared_error,r2_score,precision_score,recall_score,f1_score,accuracy_score,confusion_matrix,roc_curve,auc,roc_auc_score,classification_report(2)定义一个集成建模过程的类
class Modeling():
def __init__(self,alg,params,cvnums):
self.alg=alg
self.name=alg.__class__.__name__
self.params=params
self.cvnums=cvnums
def grid_train_test(self,xtrain,ytrain,x_test,y_test):
grid=GridSearchCV(self.alg,self.params,cv=self.cvnums,scoring='accuracy')
grid.fit(xtrain,ytrain)
self.best_params=grid.best_params_
self.best_estimator=grid.best_estimator_
self.cv_results=grid.cv_results_
self.train_accuracy=grid.best_score_
self.best_estimator.fit(xtrain,ytrain)
self.pred_label=self.best_estimator.predict(x_test)
try:
self.pred_proba=self.best_estimator.decision_function(x_test)
except:
self.pred_proba=self.best_estimator.predict_proba(x_test)[:,1]
self.precision_score=precision_score(y_test,self.pred_label)
self.recall_score=recall_score(y_test,self.pred_label)
self.f1_score=f1_score(y_test,self.pred_label)
self.test_accuracy=accuracy_score(y_test,self.pred_label)
self.auc=round(roc_auc_score(y_test,self.pred_proba),4)
def learningcurve(self,xtrain,ytrain):
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
train_sizes,train_scores,test_scores,fit_times,_=learning_curve(self.alg,xtrain,ytrain,
cv=ShuffleSplit(n_splits=100,test_size=0.2,random_state=2),
return_times=True)
train_scores_mean=np.mean(train_scores,axis=1)
test_scores_mean=np.mean(test_scores,axis=1)
plt.rc('font',size=13)
plt.rcParams['font.sans-serif'] =['SimHei']
fig,axes=plt.subplots(1,2,figsize=(16,4))
axes[0].set_title(self.name)
axes[0].set_xlabel('训练样本数')
axes[0].set_ylabel('准确率')
axes[0].plot(train_sizes,train_scores_mean,'o-',color='r',label='训练集平均准确率')
axes[0].plot(train_sizes,test_scores_mean,'o-',color='g',label='测试集平均准确率')
axes[0].legend(loc='best')
axes[0].grid()
cv_results=pd.DataFrame(self.cv_results)
if len(self.params)==1:
CV_RESULTS=cv_results.pivot_table(values='mean_test_score',index=cv_results.columns[4])
axes[1].set_title(self.name)
axes[1].set_ylabel('准确率')
CV_RESULTS.plot(ax=axes[1],marker='o')
elif len(self.params)==2:
CV_RESULTS=cv_results.pivot_table(values='mean_test_score',index=cv_results.columns[4],columns=cv_results.columns[5])
axes[1].set_title(self.name+'_SCORE')
sns.heatmap(CV_RESULTS,annot=True,ax=axes[1])
else:
heatmap_col=[]
for i in np.arange(len(params)-1):
heatmap_col.append(cv_results.columns[5+i])
CV_RESULTS=cv_results.pivot_table(values='mean_test_score',index=cv_results.columns[4],columns=heatmap_col)
axes[1].set_title(self.name+'_SCORE')
sns.heatmap(CV_RESULTS,annot=True,ax=axes[1])
plt.subplots_adjust(wspace=0.25)(3)选取K近邻分类器、逻辑回归、支持向量机和随机森林分类器这四个模型建模
knn=Modeling(KNeighborsClassifier(),{'n_neighbors':np.linspace(1,10,10).astype('int'),'weights':['uniform','distance']},5)
knn.grid_train_test(xtrain,ytrain,x_test,y_test)
lr=Modeling(LogisticRegression(),{'C':np.linspace(0.6,1.5,10)},5)
lr.grid_train_test(xtrain,ytrain,x_test,y_test)
svm=Modeling(SVC(probability=True),{'C':np.linspace(60,100,5),'gamma':[0.22,0.24,0.26,0.28,0.30]},5)
svm.grid_train_test(xtrain,ytrain,x_test,y_test)
rf=Modeling(RandomForestClassifier(),{'n_estimators':np.linspace(50,200,4).astype('int')},5)
rf.grid_train_test(xtrain,ytrain,x_test,y_test)(4)查看并比较各模型的结果
def resulst_contrast(algclasslist):
algname=[]
best_params=[]
precision_score=[]
recall_score=[]
f1_score=[]
test_accuracy=[]
auc=[]
for alg in algclasslist:
algname.append(alg.name)
best_params.append(alg.best_params)
precision_score.append(alg.precision_score)
recall_score.append(alg.recall_score)
f1_score.append(alg.f1_score)
test_accuracy.append(alg.test_accuracy)
auc.append(round(alg.auc,4))
return pd.DataFrame({'模型':algname,'最优参数':best_params,'查准率':precision_score,'查全率':recall_score,'f1得分':f1_score,
'测试集正确率':test_accuracy,'auc':auc}).set_index('模型').sort_values(by='auc',ascending=False)
resulst_contrast([knn,lr,svm,rf])分析:可以看出,逻辑回归、支持向量机和随机森林分类器的auc都达到了0.95以上,但其中逻辑回归的查准率和预测正确率不够理想,不过这并不妨碍该模型的使用价值,因为本业务是要尽可能多得识别出潜在的个贷客户,因而相比于查准率本业务更看重查全率;而k近邻分类器虽然auc低于0.95,但其预测正确率并不低;所有模型中预测性能最好的是随机森林分类器,其f1得分和预测正确率都很高,且auc高达0.9984。
(5)绘制各模型的学习曲线
knn.learningcurve(xtrain,ytrain)
lr.learningcurve(xtrain,ytrain)
svm.learningcurve(xtrain,ytrain)
rf.learningcurve(xtrain,ytrain)分析:
1)通过左半部分的学习曲线可以看出,在交叉验证过程中除了逻辑回归以外其余三个模型的训练集准确率都处于较高水平,尤其是随机森林模型的准确率一直维持在100%,因而可能存在一定程度的过拟合问题,推测这种过拟合主要是因为在处理类别不均衡问题时进行了过采样造成的;而逻辑回归的训练集准确率随着样本量的增加不断降低,可能存在一定程度的欠拟合问题,推测主要是因为逻辑回归模型不能很好地处理非线性可分问题,从而导致模型的学习难度随着样本量的不断增加而增大,最终造成欠拟合问题。
2)K近邻:最优近邻数为1,且通过热力图可以看出模型准确率随着近邻数的增加而下降,因而不需要再进行调参。
3)逻辑回归:最优正则化系数的倒数为1.3,且通过学习曲线可以看出模型准确率在正则化系数倒数为1.3处取到最值,因而不需要再进行调参。
4)支持向量机:通过热力图可以看出,矩阵中最优系数搭配组合(误分类惩罚系数100,核函数系数0.26)周围看不出明显的能使模型准确率提升的参数变化趋势,因而不再进一步调参。
5)随机森林分类器:最优决策树个数为100,且通过学习曲线可以看出决策树个数向100两侧变化并不能带来模型准确率的提高,因而不再进一步调参。
(6)模型融合:选取预测性能前三的逻辑回归、支持向量机和随机森林分类器采用投票评估器进行融合。
from sklearn.ensemble import VotingClassifier
ensemble_voting=VotingClassifier(estimators=[('lr',lr.best_estimator),('svm',svm.best_estimator),('rf',rf.best_estimator)],voting='soft')
ensemble_voting.fit(xtrain,ytrain)
auc=roc_auc_score(y_test,ensemble_voting.predict_proba(x_test)[:,1])
print('VotingClassifier的auc为:%.4f'%(auc))分析:可以看出,融合后的auc没有单个模型的auc高,因而采用随机森林分类器作为最终模型。
(7)输出最优分类器
rf.best_estimator运用RFM模型分析用户价值度
背景概念概
用户数据化运营是互联网运营工作必备工作之一,且产品的生存必须有用户。而会员价价值度是用来评估用户的价值情况,是区分会员价值的重要性模型和参考依据,也是衡量不同营销效果的关键指标之一,我们可以通过复购率、消费频率、最近一次购买时间、最近一次购买金额等方面分析会员价值度。
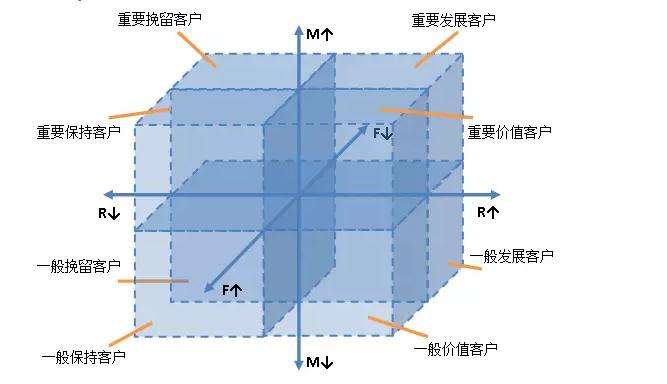
常用的价值度模型是RFM。RFM模型是根据会员最近一次购买时间R(Rencency)、购买频率F(Frequency)、购买金额M(Monetary)计算得出RFM分,通过这三个维度来评估客户的用户活跃价值。RFM模型基于一个固定时间点来做模型分析,分析的时间节点不同,所得到的结果也是不同的。
RFM模型分析步骤
1 、 设定分析数据的截止时间节点(如2018-4-1),用来做基于该时间节点的数据选取和计算。
2 、 在用户数据库中,以步骤1设定的时间节点为界限向前推一固定周期(如一周年、一个月等),选择截取每个会员的会员ID、订单时间、订单金额的原始数据集。
3 、根据获取到的原始数据集,分别计算
最近一次购买时间R(Rencency):各个会员最近的订单时间与截止时间节点的距离;
购买频率F(Frequency):以会员ID为区分,分别统计各会员ID的订单数量;
购买金额M(Monetary):将用户多个订单的订单金额求和。
4、 对R、F、M值进行分区。对于F和M变量来讲,值越大代表购买频率越高、订单金额越 高;但对R来讲值越小代表离截止时间节点越近,因此值越好。对R、F、M分别使用五分位(也可以分成其他分位,如三分位)法做数据分区,需要注意的是,对于R来讲需要倒过来划分,离截止时间越近的值划分越大。
5、 将三个值组合或相加得到总的RFM得分。这里有两种得分方式,一种是直接将三个值拼接到一起,例如RFM得分为213、131、122;一种是直接将三个值相加求得一个新的汇总值,例如RFM得分为7、6、9。在得到不同会员的RFM的之后,根据步骤5产生的两种结果有不用的应用思路:
应用思路
1:基于三个维度值做用户群体划分和解读,对用户的价值度做分析。例如得分为213的会员往往购买频率较低,针对购买频率低的客户定期发送促销活动邮件;针对得分为131的会员虽然购买频率高但是订单金额低等,这些客户往往具有较高的购买粘性,可以考虑通过关联或搭配销售的方式提升订单金额。
2:基于RFM的汇总得分评估所有会员的价值度价值,并可以做价值度排名;同时,该得分还可以作为输入维度跟其他维度一起作为其他数据分析和挖掘模型的输入变量,为分析建模提供基础。
案例详解
一、导入模块库
import numpy as np # 导入numpy库
import pandas as pd # 导入pandas库
import mysql.connector # 导入mysql连接库
import time # 导入时间库MYSQL Connector Python 数据库连接工具官方安装包http://dev.mysql.com
上面是mysql.connector库的官方连接安装包,可以对应自己的操作环境安装适应的包。
二、读取原始数据
dtypes = {'SALEDATE': object, 'SALEID': object, 'AMOUNTINFO': np.float32} # 设置每列数据类型
raw_data = pd.read_csv('sales1.csv', dtype=dtypes, index_col='USERID') # 读取数据文件提前用字典定义dtypes,便于对原始数据读取时对数据框数据类型的自定义,如未定义则为系统默认类型。本次将SALEDATE(销售时间)和SALEID(订单ID)设置为字符串对象,对
AMOUNTINFO(订单金额)设为浮点型。
该数据已直接存放在python分析系统目录下,使用pd.read_csv 读取数据文件,该数据已直接存放在python分析系统目录下不需要设置路径,可直接读取。默认的csv是以逗号为分隔,因此无需制定分隔符。按上述字典设置参数dtype,同时以用户ID为索引列。
三、对数据查看
print (raw_data.head(10)) # 打印原始数据前10条
通过head方法输出前10条数据。
print (raw_data.describe()) # 打印原始数据基本描述性信息
通过数据框的describe方法输出描述性统计信息。
在本案例中,发现数据的极值相差非常大,并且标准差也很大,说明数据波动非常明显。另外,最大值和最小值似乎有些奇怪:最大值竟然有超过 30000 元、最小值却只有 0.5 元,这两种状态都非常异常。对这些情况需要与业务部门沟通,对于低于10元的订单是否是因为优惠券订单而生成,因此对这些数据去除。
na_column = raw_data.isnull().any(axis=0) # 查看每一列是否具有缺失值
print (na_column) # 查看具有缺失值的列
缺失值对后续分析会产生影响,因此检查数据中是否有缺失值。
na_lines = raw_data.isnull().any(axis=1) # 查看每一行是否具有缺失值
print ('Total number of NA lines is: {0}'.format(na_lines.sum())) # 查看具有缺失值的行总记录
通过raw_data.isnull().any(axis=0)来判断所有列是否含有缺失信息,其中的 isnull 用来查看是否有缺失值,any 用来判断数据记录中的任何一个位置出现缺失值都会计算在内,参数 axis=0 以列查看。
print (raw_data[na_lines]) # 只查看具有缺失值的行信息
通过放回统计查看,缺失值的行数只有10条,占总体比例非常小,因此可以直接删除。
四、对数据预处理
异常值处理
sales_data = raw_data.dropna() # 丢弃带有缺失值的行记录
sales_data = sales_data[sales_data['AMOUNTINFO'] > 10] # 丢弃订单金额<=10的记录
sales_data['SALEDATE'] = pd.to_datetime(sales_data['SALEDATE'], format='%Y-%m-%d') # 将字符串转换为日期格式日期转换的目的是实现时间间隔的计算,算出 R最近时间距离天数。
通过dropna方法删除缺失值。
print (sales_data.dtypes)
分别计算 R、F、M 三个原始变量的数值
recency_value = sales_data['SALEDATE'].groupby(sales_data.index).max() # 计算原始最近一次订单时间
frequency_value = sales_data['SALEDATE'].groupby(sales_data.index).count() # 计算原始订单频率
monetary_value = sales_data['AMOUNTINFO'].groupby(sales_data.index).sum() # 计算原始订单总金额
通过数据框的 groupby 方法计算各值,以原始数据框索引为主键分别对求订单时间最大值,订单计数统计,对订单额求和。
五、计算RFM得分
deadline_date = pd.datetime(2017, 1, 1) # 指定一个时间节点,用于计算其他时间与该时间的距离
r_distance = (deadline_date - recency_value).dt.days # 计算R间隔
r_score = pd.cut(r_distance, 5, labels=[5, 4, 3, 2, 1]) # 计算R得分
f_score = pd.cut(frequency_value, 5, labels=[1, 2, 3, 4, 5]) # 计算F得分
m_score = pd.cut(monetary_value, 5, labels=[1, 2, 3, 4, 5]) # 计算M得分
pd.datetime方法指定时间节点,dt.days方法获取时间间隔天数。通过pd.cut 方法对三个变量值使用分位数做区间划分,默认设置为 5 份,同时通过 labels 标签指定区间标志。要注意的是R区分值,数值越大指离指定时间越远,因此其区间划分后的值应该越小。
rfm_list = [r_score, f_score, m_score] # 将r、f、m三个维度组成列表
rfm_column = ['r_score', 'f_score', 'm_score'] # 设置r、f、m三个维度列名
rfm_pd = pd.DataFrame(np.array(rfm_list).transpose(), dtype=np.int32,
columns=rfm_column,index=frequency_value.index) # 建立r、f、m数据框
建立 R、F、M 三个维度的值列表和名称列表,用于生成数据框时指定数据和标签。用pd.DataFrame 建立数据框。np.array 将 R、F、M 生成的值列表转换为矩阵。此时的矩阵形状是(3,51778),不符合我们需要的三列的需求,因此使用 transpose 方法对矩阵做转置处理。R、F、M 三个 Series 的索引都相同,可随便指定一列为索引列。
print (rfm_pd.head())
rfm_pd['rfm_score'] = rfm_pd['r_score'] * 0.7 + rfm_pd['f_score'] * 0.2 + rfm_pd['m_score'] * 0.1
根据业务情况来设定个权重值,如更注重用户的活跃度,次关注访问频率,最后为订单金额。
rfm_pd_1 = rfm_pd.copy()
rfm_pd_1['r_score'] = rfm_pd_1['r_score'].astype('str')
rfm_pd_1['f_score'] = rfm_pd_1['f_score'].astype('str')
rfm_pd_1['m_score'] = rfm_pd_1['m_score'].astype('str')
rfm_pd['rfm_comb']=rfm_pd_1['r_score'].str.cat(rfm_pd_1['f_score']).str.cat(rfm_pd_1['m_score'])
依照方法二中,将R、F、M 三个值组合,组成一个三位数,通过字符串组合。通过pandas 的字符串处理库 str 中的 cat 方法做字符串合并,该方法可以将右侧的数据合并到左侧
六、输出保存结果
print (rfm_pd.head()) # 打印数据前5项结果

print (rfm_pd.describe())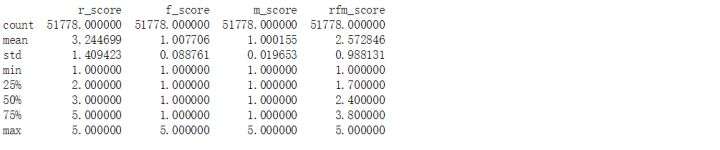
将RFM得分文件保存到本地,便于业务做进一步分析应用。
rfm_pd.to_csv('sales_rfm_score1.csv') 可以将 RFM 得分写入数据框,方便为其他模型做输入维度,这里使用MySQL 官方连接程序实现。
table_name = 'sales_rfm_score1' # 要写库的表名通过 table_name='sales_rfm_score'定义要写入的表的名称,该变量会在后续表识别和写入时用到。config 定义了一个用于写入数据库的详细配置信息定义。
config = {'host': '127.0.0.1', # 默认127.0.0.1
'user': 'root', # 用户名
'password': '123456', # 密码
'port': 3306, # 端口,默认为3306
'database': 'python_data', # 数据库名称
'charset': 'gb2312' # 字符编码
}con = mysql.connector.connect(**config) # 建立mysql连接
cursor = con.cursor() # 获得游标
在将数据写入数据库之前,需要先判断数据库中是否存在要写入的表。如果不存在需要新建数据表。
cursor.execute("show tables") #
table_object = cursor.fetchall() # 通过fetchall方法获得所有数据
table_list = [] # 创建库列表for t in table_object: # 循环读出所有库
table_list.append(t[0]) # 每个每个库追加到列表if not table_name in table_list: # 如果目标表没有创建
cursor.execute('''
CREATE TABLE %s (
user_id VARCHAR(20),
r_score int(2),
f_score int(2),
m_score int(2),
rfm_score DECIMAL(10,2),
rfm_comb VARCHAR(10),
insert_date VARCHAR(20)
)ENGINE=InnoDB DEFAULT CHARSET=gb2312
''' % table_name) # 创建新表user_id = rfm_pd.index # 索引列
rfm_score = rfm_pd['rfm_score'] # RFM加权得分列
rfm_comb = rfm_pd['rfm_comb'] # RFM组合得分列
timestamp = time.strftime('%Y-%m-%d', time.localtime(time.time())) # 写库日期print ('Begin to insert data into table {0}...'.format(table_name)) # 输出开始写库的提示信息
for i in range(rfm_pd.shape[0]): # 设置循环次数并依次循环
insert_sql = "INSERT INTO `%s` VALUES ('%s',%s,%s,%s,%s,'%s','%s')" % \
(table_name, user_id[i], r_score.iloc[i], f_score.iloc[i], m_score.iloc[i], rfm_score.iloc[i],rfm_comb.iloc[i], timestamp) # 写库SQL依据
cursor.execute(insert_sql) # 执行SQL语句,execute函数里面要用双引号
con.commit() # 提交命令
cursor.close() # 关闭游标
con.close() # 关闭数据库连接
print ('Finish inserting, total records is: %d' % (i + 1)) # 打印写库结果
七、结论:
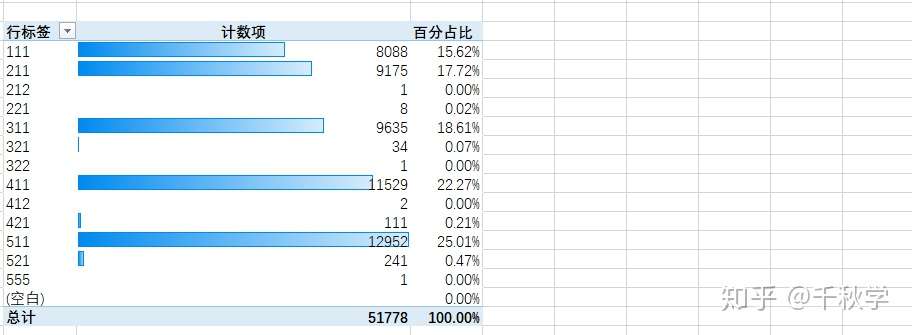
公司的会员中 99%以上的客户消费状态都不容乐观,主要体现在消费频率低 R、消费总金额低 M。——经过分析,这里主要由于其中有一个用户(ID 为 74270)消费金额非常高,导致做 5 分位时收到最大值的影响,区间向大值域区偏移。
公司中有一些典型客户的整个贡献特征明显,重点是 RFM 得分为 555 的用户(ID 为 74270),该用户不仅影响了订单金额高,而且其频率和购买新鲜度和消费频率都非常高,应该引起会员管理部门的重点关注。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝